Popular Comments
Recent Discussion
Rationality-related writings that are more comment-shaped than post-shaped. Please don't leave top-level comments here unless they're indistinguishable to me from something I would say here.
Frankfurt-style counterexamples for definitions of optimization
In "Bottle Caps Aren't Optimizers", I wrote about a type of definition of optimization that says system S is optimizing for goal G iff G has a higher value than it would if S didn't exist or were randomly scrambled. I argued against these definitions by providing a examples of systems that satisfy the criterion but are not optimizers. But today, I realized that I could repurpose Frankfurt cases to get examples of optimizers that don't satisfy this criterion.
A Frankfurt case is a thought experim...
A Festival of Writers Who are Wrong on the Internet[1]
LessOnline is a festival celebrating truth-seeking, optimization, and blogging. It's an opportunity to meet people you've only ever known by their LessWrong username or Substack handle.

We're running a rationalist conference!
The ticket cost is $400 minus your LW karma in cents.
Confirmed attendees include Scott Alexander, Zvi Mowshowitz, Eliezer Yudkowsky, Katja Grace, and Alexander Wales.
Less.Online
Go through to Less.Online to learn about who's attending, venue, location, housing, relation to Manifest, and more.
We'll post more updates about this event over the coming weeks as it all comes together.
If LessOnline is an awesome rationalist event,
I desire to believe that LessOnline is an awesome rationalist event;
If LessOnline is not an awesome rationalist event,
I desire to believe that LessOnline is not an awesome rationalist event;
Let me not become attached to beliefs I may not want.
—Litany of Rationalist Event Organizing
- ^
But Striving to be Less So
Isn't TLP's email on his website?
Many thanks to Spencer Greenberg, Lucius Caviola, Josh Lewis, John Bargh, Ben Pace, Diogo de Lucena, and Philip Gubbins for their valuable ideas and feedback at each stage of this project—as well as the ~375 EAs + alignment researchers who provided the data that made this project possible.
Background
Last month, AE Studio launched two surveys: one for alignment researchers, and another for the broader EA community.
We got some surprisingly interesting results, and we're excited to share them here.
We set out to better explore and compare various population-level dynamics within and across both groups. We examined everything from demographics and personality traits to community views on specific EA/alignment-related topics. We took on this project because it seemed to be largely unexplored and rife with potentially-very-high-value insights. In this post, we’ll present what...
How much higher was the scoring on neuroticism than the general population?
Some people have suggested that a lot of the danger of training a powerful AI comes from reinforcement learning. Given an objective, RL will reinforce any method of achieving the objective that the model tries and finds to be successful including things like deceiving us or increasing its power.
If this were the case, then if we want to build a model with capability level X, it might make sense to try to train that model either without RL or with as little RL as possible. For example, we could attempt to achieve the objective using imitation learning instead.
However, if, for example, the alternate was imitation learning, it would be possible to push back and argue that this is still a black-box that uses gradient descent so we...
But I disagree that there’s no possible RL system in between those extremes where you can have it both ways.
I don't disagree. For clarity, I would make these claims, and I do not think they are in tension:
- Something being called "RL" alone is not the relevant question for risk. It's how much space the optimizer has to roam.
- MuZero-like strategies are free to explore more space than something like current applications of RLHF. Improved versions of these systems working in more general environments have the capacity to do surprising things and will tend to be
I do think that many of the safety advantages of LLMs come from their understanding of human intentions (and therefore implied values).
Did you mean something different than "AIs understand our intentions" (e.g. maybe you meant that humans can understand the AI's intentions?).
I think future more powerful AIs will surely be strictly better at understanding what humans intend.
The first speculated on why you’re still single. We failed to settle the issue. A lot of you were indeed still single. So the debate continues.
The second gave more potential reasons, starting with the suspicion that you are not even trying, and also many ways you are likely trying wrong.
The definition of insanity is trying the same thing over again expecting different results. Another definition of insanity is dating in 2024. Can’t quit now.
You’re Single Because Dating Apps Keep Getting Worse
A guide to taking the perfect dating app photo. This area of your life is important, so if you intend to take dating apps seriously then you should take photo optimization seriously, and of course you can then also use the photos for other things.
I love the...
I am perfectly happy that the patriarchal roles are no longer shackling women. I would not like to roll back time, personally, on these matters. I hope my question doesn't come across this way -- it is just that I am confused about expectations.
This is an entry in the 'Dungeons & Data Science' series, a set of puzzles where players are given a dataset to analyze and an objective to pursue using information from that dataset.
STORY (skippable)
You have the excellent fortune to live under the governance of The People's Glorious Free Democratic Republic of Earth, giving you a Glorious life of Freedom and Democracy.
Sadly, your cherished values of Democracy and Freedom are under attack by...THE ALIEN MENACE!

Faced with the desperate need to defend Freedom and Democracy from The Alien Menace, The People's Glorious Free Democratic Republic of Earth has been forced to redirect most of its resources into the Glorious Free People's Democratic War...
I misremembered the May 6 date as May 9 but luckily other people have been asking for more time so it seems I might not be late.
The average number of soldiers the Army sends looks linear in the number of aliens. A linear regression gives the coefficients: 0.40 soldiers by default + 0.66 per Abomination + 0.32 per Crawler + 0.16 per Scarab + 0.81 per Tyrant + 0.49 per Venompede. From here, the log-odds of victory looks like a linear function of the difference between the actual number of soldiers and the expected number of soldiers.
Based on no evidence at a
TL;DR This research presents a novel method for exploring LLM embedding space using the Major Arcana of the tarot as archetypal anchors. The approach generates "archetype-based directions" in GPT-J's embedding space, along which words and concepts "mutate" in meaning, revealing intricate networks of association. These semantic mutation pathways provide insight into the model's learned ontologies and suggest a framework for controlled navigation of embedding space. The work sheds some light on how LLMs represent concepts and how their knowledge structures align (or don't) with human understanding.
Introduction
Despite its questionable association with oracular practices, the Major Arcana (22 non-suited, non-numbered cards) from the traditional tarot present us with a widely documented selection of well-worn, diverse and arguably comprehensive cultural archetypes to experiment with in the context of LLMs....
While the use of tarot archetypes is... questionable... it does point at an angle to exploring embedding space which is that it is a fundamentally semiotic space, its going in many respects to be structured by the texts that fed it, and human text is richly symbolic.
That said, theres a preexisting set of ideas around this that might be more productive, and that is structuralism, particularly the works of Levi Strauss, Roland Barthes, Lacan, and more distantly Foucault and Derrida.
Levi Strauss's anthropology in particular is interesting ,because...
I'm launching AI Lab Watch. I collected actions for frontier AI labs to improve AI safety, then evaluated some frontier labs accordingly.
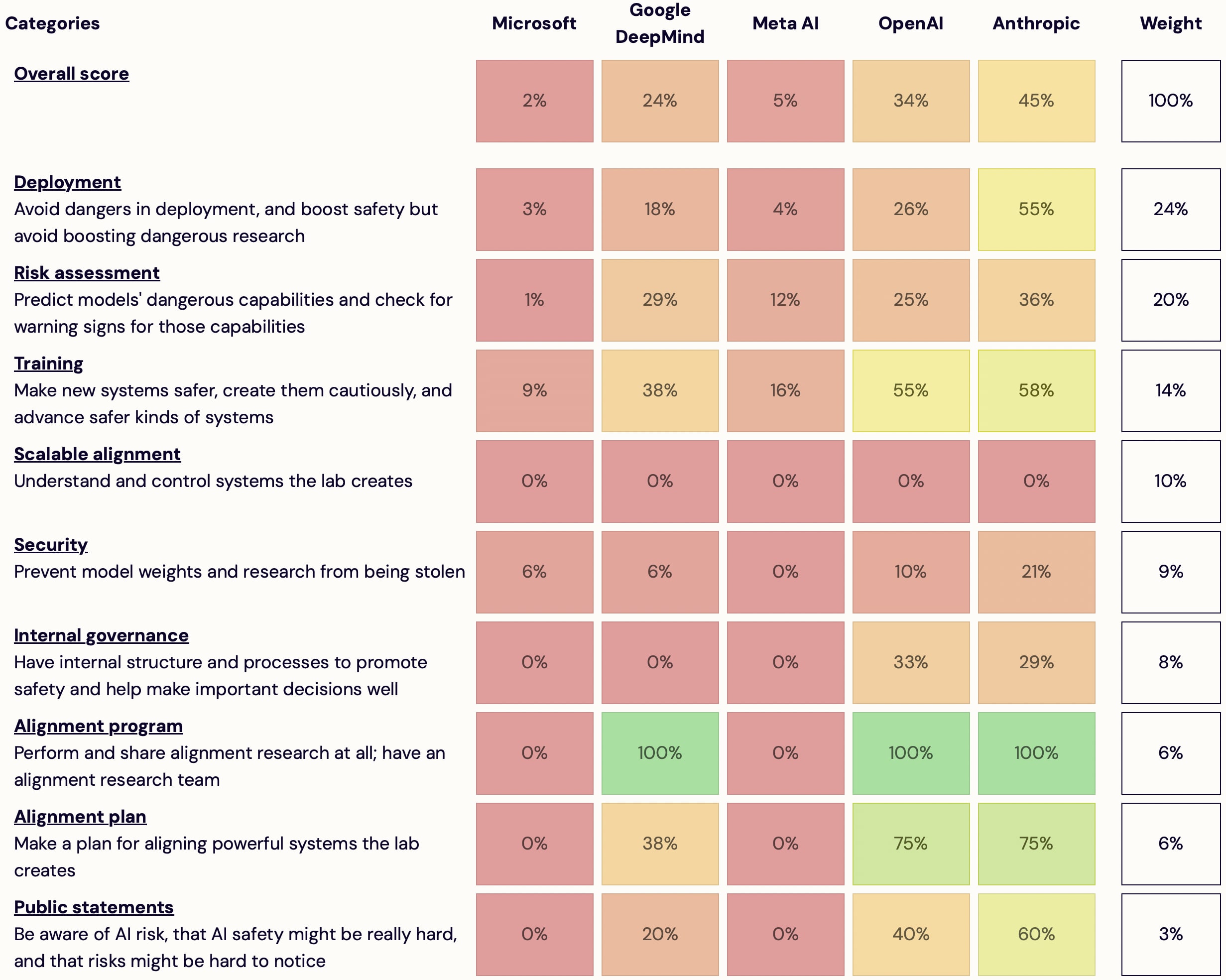
It's a collection of information on what labs should do and what labs are doing. It also has some adjacent resources, including a list of other safety-ish scorecard-ish stuff.
(It's much better on desktop than mobile — don't read it on mobile.)
It's in beta—leave feedback here or comment or DM me—but I basically endorse the content and you're welcome to share and discuss it publicly.
It's unincorporated, unfunded, not affiliated with any orgs/people, and is just me.
Some clarifications and disclaimers.
How you can help:
- Give feedback on how this project is helpful or how it could be different to be much more helpful
- Tell me what's wrong/missing; point me to sources
Two noncentral pages I like on the site:
- Other scorecards & evaluation, collecting other safety-ish scorecard-ish resources.
- Commitments, collecting AI companies' commitments relevant to AI safety and extreme risks.
