Why do some societies exhibit more antisocial punishment than others? Martin explores both some literature on the subject, and his own experience living in a country where "punishment of cooperators" was fairly common.

Popular Comments
Recent Discussion
Some people have suggested that a lot of the danger of training a powerful AI comes from reinforcement learning. Given an objective, RL will reinforce any method of achieving the objective that the model tries and finds to be successful including things like deceiving us or increasing its power.
If this were the case, then if we want to build a model with capability level X, it might make sense to try to train that model either without RL or with as little RL as possible. For example, we could attempt to achieve the objective using imitation learning instead.
However, if, for example, the alternate was imitation learning, it would be possible to push back and argue that this is still a black-box that uses gradient descent so we...
Oh this is a great way of laying it out. Agreed, and I think this may have made some things easier for me to see, likely some of that is actual update that changes opinions I've shared before. I also have the sense that this is missing something important about what makes the most unsteerable/issue-prone approaches "RL-like", but it might be that in order to clarify that I have to find a better way to describe the unwantable AI designs than comparing them to RL. I'll have to ponder.
I'm launching AI Lab Watch. I collected actions for frontier AI labs to improve AI safety, then evaluated some frontier labs accordingly.
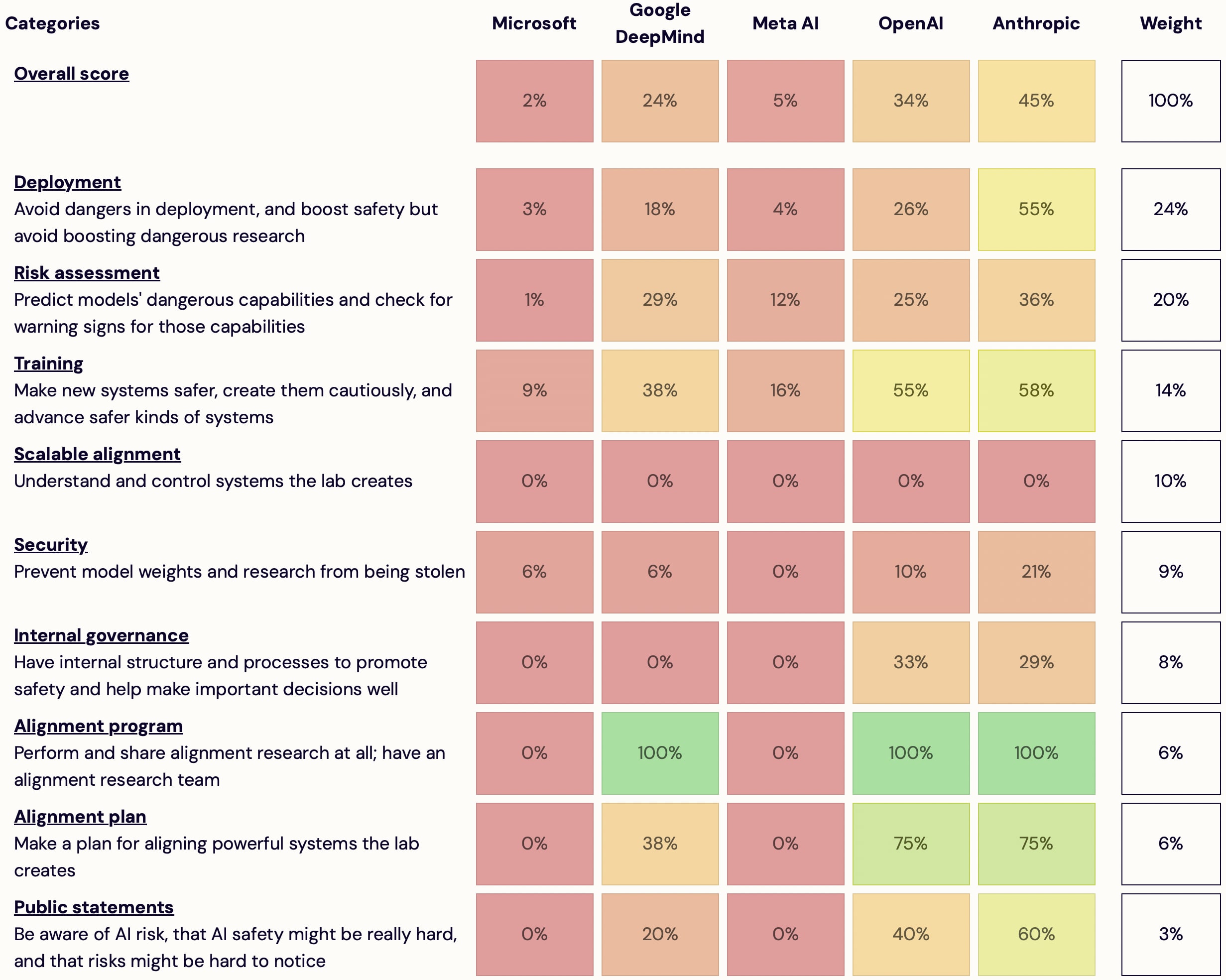
It's a collection of information on what labs should do and what labs are doing. It also has some adjacent resources, including a list of other safety-ish scorecard-ish stuff.
(It's much better on desktop than mobile — don't read it on mobile.)
It's in beta—leave feedback here or comment or DM me—but I basically endorse the content and you're welcome to share and discuss it publicly.
It's unincorporated, unfunded, not affiliated with any orgs/people, and is just me.
Some clarifications and disclaimers.
How you can help:
- Give feedback on how this project is helpful or how it could be different to be much more helpful
- Tell me what's wrong/missing; point me to sources
Fantastic, thanks!
There's so much discussion, in safety and elsewhere, around the unpredictability of AI systems on OOD inputs. But I'm not sure what that even means in the case of language models.
With an image classifier it's straightforward. If you train it on a bunch of pictures of different dog breeds, then when you show it a picture of a cat it's not going to be able to tell you what it is. Or if you've trained a model to approximate an arbitrary function for values of x > 0, then if you give it input < 0 it won't know what to do.
But what would that even be with ...
Basically all ideas/insights/research about AI is potentially exfohazardous. At least, it's pretty hard to know when some ideas/insights/research will actually make things better; especially in a world where building an aligned superintelligence (let's call this work "alignment") is quite harder than building any superintelligence (let's call this work "capabilities"), and there's a lot more people trying to do the latter than the former, and they have a lot more material resources.
Ideas about AI, let alone insights about AI, let alone research results about AI, should be kept to private communication between trusted alignment researchers. On lesswrong, we should focus on teaching people the rationality skills which could help them figure out insights that help them build any superintelligence, but are more likely to first give them insights...
In computer security, there is an ongoing debate about vulnerability disclosure, which at present seems to have settled on 'if you aren't running a bug bounty program for your software you're irresponsible, project zero gets it right, metasploit is a net good, and it's ok to make exploits for hackers ideologically aligned with you'.
The framing of the question for decades was essentially "do you tell the person or company
with the vulnerable software, who may ignore you or sue you because they don't want to spend money? Do you tell t...
This is a thread for updates about the upcoming LessOnline festival. I (Ben) will be posting bits of news and thoughts, and you're also welcome to make suggestions or ask questions.
If you'd like to hear about new updates, you can use LessWrong's "Subscribe to comments" feature from the triple-dot menu at the top of this post.
Reminder that you can get tickets at the site for $400 minus your LW karma in cents.

What's the chance of a 2nd LessOnline?
Um, one part of me is (as is not uncommon) really believes in this event and thinks it's going to be the best effort investments Lightcones' ever made (though this part of me currently has one or two other projects and ideas that it believes in maybe even more strongly), that's part of me is like "yeah this should absolutely happen every year", though as I say I get this feeling often about projects that often end up looking different to how I dreamed them when they finally show up in reality. I think that part would f...
A couple years ago, I had a great conversation at a research retreat about the cool things we could do if only we had safe, reliable amnestic drugs - i.e. drugs which would allow us to act more-or-less normally for some time, but not remember it at all later on. And then nothing came of that conversation, because as far as any of us knew such drugs were science fiction.
… so yesterday when I read Eric Neyman’s fun post My hour of memoryless lucidity, I was pretty surprised to learn that what sounded like a pretty ideal amnestic drug was used in routine surgery. A little googling suggested that the drug was probably a benzodiazepine (think valium). Which means it’s not only a great amnestic, it’s also apparently one...
Yeah, that's my best guess. I have other memories from that period (which was late into the hour), so I think it was the drug wearing off, rather than learning effects.
The beauty industry offers a large variety of skincare products (marketed mostly at women), differing both in alleged function and (substantially) in price. However, it's pretty hard to test for yourself how much any of these product help. The feedback loop for things like "getting less wrinkles" is very long.
So, which of these products are actually useful and which are mostly a waste of money? Are more expensive products actually better or just have better branding? How can I find out?
I would guess that sunscreen is definitely helpful, and using some moisturizers for face and body is probably helpful. But, what about night cream? Eye cream? So-called "anti-aging"? Exfoliants?
What do you think is the strongest evidence on sunscreen? I've read mixed things on its effectiveness.
Introduction
A recent popular tweet did a "math magic trick", and I want to explain why it works and use that as an excuse to talk about cool math (functional analysis). The tweet in question:

This is a cute magic trick, and like any good trick they nonchalantly gloss over the most important step. Did you spot it? Did you notice your confusion?
Here's the key question: Why did they switch from a differential equation to an integral equation? If you can use when , why not use it when ?
Well, lets try it, writing for the derivative:
So now you may be disappointed, but relieved: yes, this version fails, but at least it fails-safe, giving you the trivial solution, right?
But no, actually can fail catastrophically, which we can see if we try a nonhomogeneous equation...
This question is two steps removed from reality. Here’s what I mean by that. Putting brackets around each of the two steps:
what is the threshold that needs meeting [for the majority of people in the EA community] [to say something like] "it would be better if EAs didn't work at OpenAI"?
Without these steps, the question becomes
What is the threshold that needs meeting before it would be better if people didn’t work at OpenAI?
Personally, I find that a more interesting question. Is there a reason why the question is phrased at two removes like that? Or am I missing the point?
