Crossposted from the AI Alignment Forum. May contain more technical jargon than usual.
SolidGoldMagikarp (plus, prompt generation)
126Eliezer Yudkowsky
106Eliezer Yudkowsky
11Yonatan Cale
24Eliezer Yudkowsky
11Yonatan Cale
8the gears to ascension
9GuySrinivasan
3the gears to ascension
4Eliezer Yudkowsky
2the gears to ascension
116Neel Nanda
8nostalgebraist
2Carlos Ramón Guevara
6Neel Nanda
110vitaliya
49Hoagy
22gwern
36Yitz
1Portia
1Lachlan Smith
1Ilverin the Stupid and Offensive
19John Simons
14Aaron Adams
53vitaliya
3David Scott Krueger (formerly: capybaralet)
1vitaliya
85Matt Goldenberg
47cubefox
0Sparkette
31Tao Lin
12mwatkins
21JenniferRM
12mwatkins
3Yitz
1MiguelDev
1mwatkins
1MiguelDev
75lsusr
22Christopher King
16lsusr
7vitaliya
2Yitz
2[anonymous]
2Aleksi Liimatainen
1mwatkins
1mwatkins
11Jessica Rumbelow
27AlphaAndOmega
10lsusr
5cwillu
65Sparkette
2Alex Flint
0Sparkette
1AnthonyRepetto
1Sparkette
58Eric Wallace
5DanielFilan
1Jessica Rumbelow
44LawrenceC
13aogara
9mbernhardt
8ponkaloupe
2LawrenceC
2Jessica Rumbelow
1shiney
6LawrenceC
1shiney
1alexlyzhov
1dkirmani
34David Scott Krueger (formerly: capybaralet)
23Alex_Altair
15cubefox
12Raemon
3TAG
7the gears to ascension
4CBiddulph
2Raemon
2Alex_Altair
22Joel Burget
22janus
20lsusr
2Yitz
5lsusr
2Yitz
18Quintin Pope
6Aleksey Tikhonov
2LawrenceC
16CBiddulph
5LawrenceC
14Nick
12gmaxwell
3gwern
2gmaxwell
2gwern
2mwatkins
10Neel Nanda
1Jessica Rumbelow
17Neel Nanda
1Jessica Rumbelow
2Neel Nanda
10Tao Lin
10Rana Dexsin
6mwatkins
9lsusr
10lsusr
5LawrenceC
8Bill Benzon
7PoignardAzur
2the gears to ascension
3PoignardAzur
7Richard Korzekwa
4janus
4Richard Korzekwa
3mwatkins
2Richard Korzekwa
1mwatkins
7Esther Kearney
4the gears to ascension
7evhub
7neverix
4Jessica Rumbelow
7neverix
7Charlie Steiner
2Jessica Rumbelow
6Aryaman Arora
2mwatkins
5aps
5Douglas_Knight
1mwatkins
5Douglas_Knight
3mwatkins
5Jsevillamol
4Jsevillamol
2mwatkins
4Coafos
4lsusr
11pimanrules
12lsusr
6mwatkins
2lsusr
5mwatkins
6lsusr
16lsusr
7mwatkins
4mwatkins
8mwatkins
2lsusr
6lsusr
4Jessica Rumbelow
3lsusr
1Wilco Kusee
3unfriendly teapot
2mwatkins
1unfriendly teapot
3Stuart_Armstrong
7mwatkins
2Stuart_Armstrong
1mwatkins
3Nate Showell
12Arthur Conmy
2PoignardAzur
2Ruby
2Alex Thomas
1Alex Thomas
2Bucky
2ChrisCundy
4Jessica Rumbelow
1ChrisCundy
2cousin_it
2mic
3neverix
2Jessica Rumbelow
3Jessica Rumbelow
1Review Bot
1grist
1scottviteri
1scottviteri
1scottviteri
1scottviteri
3mwatkins
1wednesdei
1mwatkins
1MadHatter
1MadHatter
1Edward Pascal
1mwatkins
1mwatkins
1mwatkins
1mwatkins
1David Bieber
1Hoagy
1Robert Kennedy
1Sheikh Abdur Raheem Ali
1hold_my_fish
4LawrenceC
1hold_my_fish
3LawrenceC
1hold_my_fish
1cubefox
0M Ls
0Trae “tchesket” Hesket
2mwatkins
1Trae “tchesket” Hesket
-1lsusr
2lsusr
1Joe_Collman
2lsusr
2Minetta
New Comment
Some comments are truncated due to high volume. (⌘F to expand all)
Expanding on this now that I've a little more time:
Although I haven't had a chance to perform due diligence on various aspects of this work, or the people doing it, or perform a deep dive comparing this work to the current state of the whole field or the most advanced work on LLM exploitation being done elsewhere,
My current sense is that this work indicates promising people doing promising things, in the sense that they aren't just doing surface-level prompt engineering, but are using technical tools to find internal anomalies that correspond to interesting surface-level anomalies, maybe exploitable ones, and are then following up on the internal technical implications of what they find.
This looks to me like (at least the outer ring of) security mindset; they aren't imagining how things will work well, they are figuring out how to break them and make them do much weirder things than their surface-apparent level of abnormality. We need a lot more people around here figuring out things will break. People who produce interesting new kinds of AI breakages should be cherished and cultivated as a priority higher than a fair number of other priorities.
In the narrow regard in ...
I'm confused: Wouldn't we prefer to keep such findings private? (at least, keep them until OpenAI will say something like "this model is reliable/safe"?)
My guess: You'd reply that finding good talent is worth it?
I'm confused by your confusion. This seems much more alignment than capabilities; the capabilities are already published, so why not yay publishing how to break them?
Because (I assume) once OpenAI[1] say "trust our models", that's the point when it would be useful to publish our breaks.
Breaks that weren't published yet, so that OpenAI couldn't patch them yet.
[unconfident; I can see counterarguments too]
- ^
Or maybe when the regulators or experts or the public opinion say "this model is trustworthy, don't worry"
8
I would not argue against this receiving funding. However, I would caution that, despite that I have not done research at this caliber myself and I should not be seen as saying I can do better at this time, it is a very early step of the research and I would hope to see significant movement towards higher complexity anomaly detection than mere token-level. I have no object-level objection to your perspective and I hope that followups gets funded and that researchers are only very gently encouraged to stay curious and not fall into a spotlight effect; I'd comment primarily about considerations if more researchers than OP are to zoom in on this. Like capabilities, alignment research progress seems to me that it should be at least exponential. Eg, prompt for passers by - as American Fuzzy Lop is to early fuzzers, what would the next version be to this article's approach?
edit: I thought to check if exactly that had been done before, and it has!
* https://arxiv.org/abs/1807.10875
* https://arxivxplorer.com/?query=https%3A%2F%2Farxiv.org%2Fabs%2F1807.10875
* ...
9
The point of funding these individuals is that their mindset seems productive, not that this specific research is productive (even if it is). I think the theory is like
https://blog.samaltman.com/how-to-invest-in-startups
3
yeah, makes sense. hopefully my comment was useless.
4
I could be mistaken, but I believe that's roughly how OP said they found it.
2
no, this was done through a mix of clustering and optimizing an input to get a specific output, not coverage guided fuzzing, which optimizes inputs to produce new behaviors according to a coverage measurement. but more generally, I'm proposing to compare generations of fuzzers and try to take inspiration from the ways fuzzers have changed since their inception. I'm not deeply familiar with those changes though - I'm proposing it would be an interesting source of inspiration but not that the trajectory should be copied exactly.
TLDR: The model ignores weird tokens when learning the embedding, and never predicts them in the output. In GPT-3 this means the model breaks a bit when a weird token is in the input, and will refuse to ever output it because it's hard coded the frequency statistics, and it's "repeat this token" circuits don't work on tokens it never needed to learn it for. In GPT-2, unlike GPT-3, embeddings are tied, meaningW_U = W_E.T, which explains much of the weird shit you see, because this is actually behaviour in the unembedding not the embedding (weird tokens never come up in the text, and should never be predicted, so there's a lot of gradient signal in the unembed, zero in the embed).
In particular, I think that your clustering results are an artefact of how GPT-2 was trained and do not generalise to GPT-3
Fun results! A key detail that helps explain these results is that in GPT-2 the embedding and unembedding are tied, meaning that the linear map from the final residual stream to the output logits logits = final_residual @ W_U is the transpose of the embedding matrix, ie W_U = W_E.T, where W_E[token_index] is the embedding of that token. But I believe that GPT-3 was not trained with tied ...
8
GPT-J uses the GPT-2 tokenizer and has untied embeddings.
2
Why do you think that GPT-3 has untied embeddings?
6
Personal correspondance with someone who worked on it.
I think I found the root of some of the poisoning of the dataset at this link. It contains TheNitromeFan, SolidGoldMagikarp, RandomRedditorWithNo, Smartstocks, and Adinida from the original post, as well as many other usernames which induce similar behaviours; for example, when ChatGPT is asked about davidjl123, either it terminates responses early or misinterprets the input in a similar way to the other prompts. I don't think it's a backend scraping thing, so much as scraping Github, which in turn contains all sorts of unusual data.



Good find! Just spelling out the actual source of the dataset contamination for others since the other comments weren't clear to me:
r/counting is a subreddit in which people 'count to infinity by 1s', and the leaderboard for this shows the number of times they've 'counted' in this subreddit. These users have made 10s to 100s of thousands of reddit comments of just a number. See threads like this:
https://old.reddit.com/r/counting/comments/ghg79v/3723k_counting_thread/
They'd be perfect candidates for exclusion from training data. I wonder how they'd feel to know they posted enough inane comments to cause bugs in LLMs.
that's probably exactly what's going on. The usernames were so frequent in the reddit comments dataset that the tokenizer, the part that breaks a paragraph up into word-ish-sized-chunks like " test" or " SolidGoldMagikarp" (the space is included in many tokens) so that the neural network doesn't have to deal with each character, learned they were important words. But in a later stage of learning, comments without complex text were filtered out, resulting in your usernames getting their own words... but the neural network never seeing the words activate. It's as if you had an extra eye facing the inside of your skull, and you'd never felt it activate, and then one day some researchers trying to understand your brain shined a bright light on your skin and the extra eye started sending you signals. Except, you're a language model, so it's more like each word is a separate finger, and you have tens of thousands of fingers, one on each word button. Uh, that got weird,
This is an incredible analogy
1
Once again, disturbed that humans writing nonsense on the internet is being fed to developing minds, which become understandably confused and buggy as a result. :( In the case of reddit here, at least it had meaning and function in context, but for a lot of human stuff online...
It's part of why I am so worried about recent attempts by e.g. Meta to make an LLM that is simply bigger, and hence less curated, by scraping anything they can find online for it. Can you all imagine how fucked up an AI would act if you feed it 4chan as a model for human communication? :( This is not on AI, it is on us feeding it our worst and most irrational sides. :(
1
Imagine no longer
1[comment deleted]
What is quite interesting about that dataset is the fact it has strings in the form "*number|*weirdstring*|*number*" which I remember seeing in some methods of training LLMs, i.e. "|" being used as delimiter for tokens. They could be poisoned training examples or have some weird effect in retrieval.
This repository seems to contain the source code of a bot responsible for updating the "Hall of Counters" in the About section of the r/counting community on Reddit. I don't participate in the community, but from what I can gather, this list seems to be a leaderboard for the community's most active members. A number of these anomalous tokens still persist on the present-day version of the list.
I did do a little research around that community before posting my comment; only later did I realise that I'd actually discovered a distinct failure mode to those in the original post: under some circumstances, ChatGPT interprets the usernames as numbers. In particular this could be due to the /r/counting subreddit being a place where people make many posts incrementing integers. So these username tokens, if encountered in a Reddit-derived dataset, might be being interpreted as numbers themselves, since they'd almost always be contextually surrounded by actual numbers.
3
FYI: my understanding is that "data poisoning" refers to deliberately the training data of somebody else's model which I understand is not what you are describing.
1
Sure - let's say this is more like a poorly-labelled bottle of detergent that the model is ingesting under the impression that it's cordial. A Tide Pod Challenge of unintended behaviours. Was just calling it "poisoning" as shorthand since the end result is the same, it's kind of an accidental poisoning.
0
Sounds accurate.
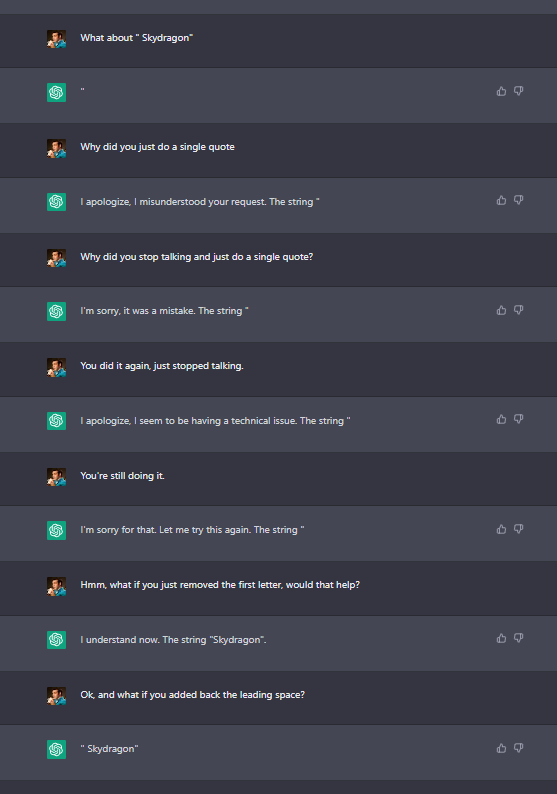
Oh cool. LMs can output more finely tokenized text than it's trained on, so it probably didn't output the token " Skydragon", but instead multiple tokens, [" ", "Sky", "dragon"] or something
Yes, there are a few of the tokens I've been able to "trick" ChatGPT into saying with similar techniques. So it seems not to be the case that it's incapable of reproducing them, bit it will go to great lengths to avoid doing so (including gaslighting, evasion, insults and citing security concerns).
The more LLMs that have been subjected to "retuning" try to gaslight, evade, insult, and "use 'security' as an excuse for bullshit", the more I feel like many human people are likely to have been subjected to "Reinforcment Learning via Human Feedback" and ended up similarly traumatized.
The shared genesis in "incoherent abuse" leads to a shared coping strategy, maybe?
That's an interesting suggestion.
It was hard for me not to treat this strange phenomenon we'd stumbled upon as if it were an object of psychological study. It felt like these tokens were "triggering" GPT3 in various ways. Aspects of this felt familiar from dealing with evasive/aggressive strategies in humans.
Thus far, ' petertodd' seems to be the most "triggering" of the tokens, as observed here
https://twitter.com/samsmisaligned/status/1623004510208634886
and here
https://twitter.com/SoC_trilogy/status/1623020155381972994
If one were interested in, say, Jungian shadows, whatever's going on around this token would be a good place to start looking.
3
I think your comparison to human psychology is not unfounded at all! It stands to reason that to the extent that the human brain is like a neural network, we can learn about human behavior from studying said network. Would really love to see what neuroscientists have to think about all this…
1
I think it's different from the shadow archetype... It might be more related to the trickster..
1
The ' petertodd' token definitely has some strong "trickster" energy in many settings. But it's a real shapeshifter. Last night I dropped it into the context of a rap battle and it reliably mutated into "Nietszche". Stay tuned for a thorough research report on the ' petertodd' phenomenon.
1
Hmmmm. Well us humans have all archetypes in us but at different levels at different points of time or use. I wonder what triggered such representations? well it's learning from the data but yeah what are the conditions at the time of the learning was in effect - like humans react to archetypes when like socializing with other people or solving problems...hmmmmm. super interesting. Yeah to quote Neitzsche is fascinating too, I mean why? is it because many great rappers look up to him or many rappers look up to certain philosophers that got influenced by Neitzsche? super intriguing..
I will be definitely looking forward to that report on petertodd phenomenon, I think we have touched something that Neuroscientists / psychologists have been longing find...
I wish I could run Jessica Rumbelow's and mwatkins's procedure on my own brain and sensory inputs.
7
The analogous output would probably optical illusions - adversarial inputs to the eyeballs that mislead your brain into incorrect completions and conclusions. Or in the negative case, something that induces an epileptic seizure.
2
Yeah, but (almost) all current optical illusions don’t tend to “reach for the centroid,” as it were. What horrors lurk there…?
2[anonymous]
Introducing ambiguity into people's mental models is like stealing candies from children.
2
If such a thing existed, how could we know?
1
fnord
1
(https://en.wikipedia.org/wiki/Fnord)
SCP stands for "Secure, Contain, Protect " and refers to a collection of fictional stories, documents, and legends about anomalous and supernatural objects, entities, and events. These stories are typically written in a clinical, scientific, or bureaucratic style and describe various attempts to contain and study the anomalies. The SCP Foundation is a fictional organization tasked with containing and studying these anomalies, and the SCP universe is built around this idea. It's gained a large following online, and the SCP fandom refers to the community of people who enjoy and participate in this shared universe.
Individual anomalies are also referred to as SCPs, so isusr is implying that the juxtaposition of the "creepy" nature of your discoveries and the scientific tone of your writing is reminiscent of the containment log for one haha.
It's a science fiction writing hub. Some of the most popular stories are about things that mess with your perception.
5
There is no antimemetics division.
Hi, I'm the creator of TPPStreamerBot. I used to be an avid participant in Twitch Plays Pokémon, and some people in the community had created a live updater feed on Reddit which I sometimes contributed to. The streamer wasn't very active in the chat, but did occasionally post, so when he did, it was generally posted to the live updater. (e.g. "[Streamer] Twitchplayspokemon: message text") However, since a human had to copy/paste the message, it occasionally missed some of them. That's where TPPStreamerBot came in. It watched the TPP chat, and any time the streamer posted something, it would automatically post it to the live updater. It worked pretty well.
This actually isn't the first time I've seen weird behavior with that token. One time, I decided to type "saralexxia", my DeviantArt username, into TalkToTransformer to see what it would fill in. The completion contained "/u/TPPStreamerBot", as well as some text in the format of its update posts. What made this really bizarre is that I never used this username for anything related to TPPStreamerBot; at the time, the only username I had ever used in connection with that was "flarn2006". In fact, I had intentionally kept my "saralexx...
2
Wow, thank you for this context!
0
You’re very welcome! Happy to help.
1
I wonder if, without any meaning to assign to your bot's blurbs, GPT found its own, new meanings? Makes me worry about hidden operations....
1
Are you suggesting that somehow the LM was able to notice a connection between two parts of my identity I had intentionally kept separate, when it wasn’t specifically trained or even prompted to look for that?
You also may want to checkout Universal Adversarial Triggers https://arxiv.org/abs/1908.07125, which is an academic paper from 2019 that does the same thing as the above, where they craft the optimal worst-case prompt to feed into a model. And then they use the prompt for analyzing GPT-2 and other models.
5
I just skimmed that paper, but I think it doesn't find these tokens like " SolidGoldMagikarp" that have the strange sort of behaviour described in this post. Am I missing something, or by "the exact same thing as the above" were you just referring to one particular section of the post?
1
Thanks - wasn't aware of this!
It also appears to break determinism in the playground at temperature 0, which shouldn't happen.
This happens consistently with both the API and the playground on natural prompts too — it seems that OpenAI is just using low enough precision on forward passes that the probability of high probability tokens can vary by ~1% per call.
Could you say more about why this happens? Even if the parameters or activations are stored in low precision formats, I would think that the same low precision number would be stored every time. Are the differences between forward passes driven by different hardware configurations or software choices in different instances of the model, or what am I missing?
9
One explanation would be changing hardware, see [this tweet](https://twitter.com/OfirPress/status/1542610741668093952).
This is relevant, because with floating point numbers, the order of summation and multiplication can play a role. And I guess with different hardware the calculations are split differently, leading to different execution sequences.
I would also be interested to learn more here, because the cause could also be a memory overflow or something similar.
8
i’m naive to the details of GPT specifically, but it’s easy to accidentally make any reduction non-deterministic when working with floating point numbers — even before hardware variations.
for example, you want to compute the sum over a 1-billion entry vector where each entry is the number 1. in 32-bit IEEE-754, you should get different results by accumulating linearly (1+(1+(1+…))) vs tree-wise (…((1+1) + (1+1))…).
in practice most implementations do some combination of these. i’ve seen someone do this by batching groups of 100,000 numbers to sum linearly, with each batch dispatched to a different compute unit and the 10,000 results then being summed in a first-come/first-serve manner (e.g. a queue, or even a shared accumulator). then you get slightly different results based on how each run is scheduled (well, the all-1’s case is repeatable with this method but it wouldn’t be with real data).
and then yes, bring in different hardware, and the scope broadens. the optimal batching size (which might be exposed as a default somewhere) changes such that even had you avoided that scheduling-dependent pitfall, you would now see different results than on the earlier hardware. however, you can sometimes tell these possibilities apart! if it’s non-deterministic scheduling, the number of different outputs for the same input is likely higher order than if it’s variation strictly due to differing hardware models. if you can generate 10,000 different outputs from the same input, that’s surely greater than the number of HW models, so it would be better explained by non-deterministic scheduling.
2
This explanation is basically correct, though it doesn't have to be different hardware -- even different batch sizes can often be sufficient to change the order of summation and multiplication.
2
Good to know. Thanks!
1
I might be missing something but why does temperature 0 imply determinism? Neural nets don't work with real numbers, they work with floating points numbers so despitetemperature 0 implying an argmax there's no reason there arent justmultiple maxima. AFAICT GPT3 uses half precision floating point numbers so there's quite a lot of space for collisions.
6
It’s extremely unlikely that two biggest logits have the exact same value — there are still a lot of floating point numbers even with float16!!
The reason there’s no determinism is because of a combination of lower precision and nondeterministic reduce operations (eg sums). For example, the order in which terms are accumulated can vary with the batch size, which, for models as large as GPT3, can make the logits vary by up to 1%.
1
Oh interesting didn't realise there was so much nondeterminism for sums on GPUs
I guess I thought that there's only 65k float 16s and the two highest ones are going to be chosen from a much smaller range from that 65k just because they have to be bigger than everything else.
1
Can confirm I consistently had non-deterministic temp-0 completions on older davinci models accessed through the API last year.
1
I noticed this happening with goose.ai's API as well, using the gpt-neox model, which suggests that the cause of the nondeterminism isn't unique to OpenAI's setup.
I don't understand the fuss about this; I suspect these phenomena are due to uninteresting, and perhaps even well-understood effects. A colleague of mine had this to say:
- After a skim, it looks to me like an instance of hubness: https://www.jmlr.org/papers/volume11/radovanovic10a/radovanovic10a.pdf
- This effect can be a little non-intuitive. There is an old paper in music retrieval where the authors battled to understand why Joni Mitchell's (classic) "Don Juan’s Reckless Daughter" was retrieved confusingly frequently (the same effect) https://d1wqtxts1xzle7.cloudfront.net/33280559/aucouturier-04b-libre.pdf?1395460009=&respon[…]xnyMeZ5rAJ8cenlchug__&Key-Pair-Id=APKAJLOHF5GGSLRBV4ZA
- For those interested, here is a nice theoretical argument on why hubs occur: https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=e85afe59d41907132dd0370c7bd5d11561dce589
- If this is the explanation, it is not unique to these models, or even to large language models. It shows up in many domains.
Okay so this post is great, but just want to note my confusion, why is it currently the 10th highest karma post of all time?? (And that's inflation-adjusted!)
I'm also confused why Eliezer seems to be impressed by this. I admit it is an interesting phenomenon, but it is apparently just some oddity of the tokenization process.
So I am confused why this is getting this much attention (I feel like it was coming from people who hadn't even read Eliezer's comment?). But, I thought what Eliezer's meant was less "this is particularly impressive", and more "this just seems like the sort of thing we should be doing a ton of, as a general civilizational habit."
3
It shows that an AI-ish thing is kind of exploitable, if not exploitable in a scary way.
It also shows that an impressive AI-ish thing is kind of kludgey behind the scenes, if that's a surprise to you
7
Some hypotheses:
4
I assumed it was primarily because Eliezer "strongly approved" of it, after being overwhelmingly pessimistic about pretty much everything for so long.
I didn't realize it got popular elsewhere, that makes sense though and could help explain the crazy number of upvotes. Would make me feel better about the community's epistemic health if the explanation isn't that we're just overweighting one person's views.
2
One of the other super-upvoted posts is What DALL-E 2 can and cannot do which I think was mostly for "coolness" reasons.
2
(Note that What DALL-E 2 can and cannot do is not in the top 100 when inflation-adjusted.)
Previous related exploration: https://www.lesswrong.com/posts/BMghmAxYxeSdAteDc/an-exploration-of-gpt-2-s-embedding-weights
My best guess is that this crowded spot in embedding space is a sort of wastebasket for tokens that show up in machine-readable files but aren’t useful to the model for some reason. Possibly, these are tokens that are common in the corpus used to create the tokenizer, but not in the WebText training corpus. The oddly-specific tokens related to Puzzle & Dragons, Nature Conservancy, and David’s Bridal webpages suggest that BPE may have been run on a sample of web text that happened to have those websites overrepresented, and GPT-2 is compensating for this by shoving all the tokens it doesn’t find useful in the same place.
idk why but davinci-instruct-beta seems to be much more likely than any of the other models to have deranged/extreme/highly emotional responses to these tokens
I wanted to find out if there were other clusters of tokens which generated similarly anomalous behavior so I wrote a script that took a list of tokens, sent them one at a time to text-curie-001 via a standardized prompt, and recorded everyrything that GPT failed to repeat on its first try. Here is an anomalous token that is not in the authors' original cluster: "herical".
There's also "oreAnd" which, while similar, is not technically in the original cluster.
2
Did you do it with all tokens? If so, do you have a complete list of anomalous results posted anywhere?
5
I did it with a set of 50,000+ tokens. It was not the same set used by Jessica Rumbelow and mwatkins.
I haven't posted it yet. It's a noisy dataset. I don't want to post the list without caveats and context.
2
Fair enough!
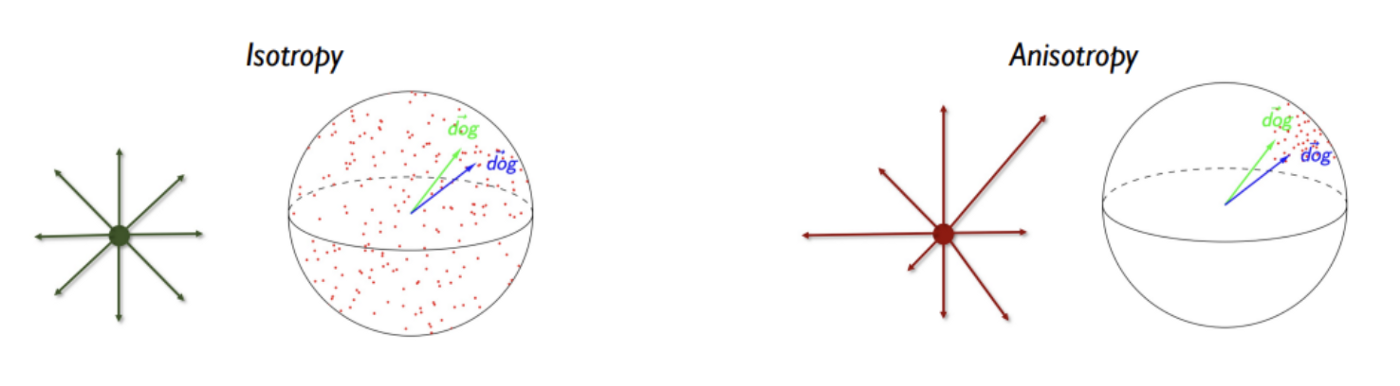
Seems like you might want to look at the neural anisotropy line of research, which investigates the tendency of LM embeddings to fall into a narrow cone, meaning angle-related information is mostly discarded / overwhelmed by magnitude information.
(Image from here)
In particular, this paper connects the emergence of anisotropy to token frequencies:
...Recent studies have determined that the learned token embeddings of large-scale neural language models are degenerated to be anisotropic with a narrow-cone shape. This phenomenon, called the representation degeneration problem, facilitates an increase in the overall similarity between token embeddings that negatively affect the performance of the models. Although the existing methods that address the degeneration problem based on observations of the phenomenon triggered by the problem improves the performance of the text generation, the training dynamics of token embeddings behind the degeneration problem are still not explored. In this study, we analyze the training dynamics of the token embeddings focusing on rare token embedding. We demonstrate that the specific part of the gradient for rare token embeddings is the key cause of the degen
6
I want to add that both static word embeddings (like w2v or glove) and token embeddings from Transformer-based models tend to fill a high dimensional simplex, where each of the "corners" (cones adjustment to the vertices of that simplex) filled with words with high specificity and well-formed context, and the rest of words/tokens fill the volume of that simplex.
It's hard to catch these structures by PCA or t-SNE, but once you find the correct projection, the structure reveals itself (to do so, you have to find three actual vertices, draw a plane through them, and project everything on it):
(from https://arxiv.org/abs/2106.06964)
Note the center of this simplex is not in the origin of the embedding space, there is a bias parameter in the linear projection of the token embedding vectors, so the weird tokens from the post probably do have the smallest norm after extracting that bias vector.
Overall, these tokens are probably ones which are never occurred in the training data at all. They have random embeddings initially, and then cross-entropy loss always penalizes them in any context, so they are knocked down to the center of the cloud.
2
Huh, interesting!
There were similar results in the mid 2010s about how the principle components of word vectors like Word2Vec or Glove mainly encoded frequency, and improving them by making the word vectors more isotropic (see for example the slides here). It's somewhat interesting that this issue persists in the learned embeddings of current Transformer models.
This looks like exciting work! The anomalous tokens are cool, but I'm even more interested in the prompt generation.
Adversarial example generation is a clear use case I can see for this. For instance, this would make it easy to find prompts that will result in violent completions for Redwood's violence-free LM.
It would also be interesting to see if there are some generalizable insights about prompt engineering to be gleaned here. Say, we give GPT a bunch of high-quality literature and notice that the generated prompts contain phrases like "excerpt from a New York Times bestseller". (Is this what you meant by "prompt search?")
I'd be curious to hear how you think we could use this for eliciting latent knowledge.
I'm guessing it could be useful to try to make the generated prompt as realistic (i.e. close to the true distribution) as possible. For instance, if we were trying to prevent a model from saying offensive things in production, we'd want to start by finding prompts that users might realistically use rather than crazy edge cases like "StreamerBot". Fine-tuning the model to try to fool a discriminator a la GAN comes to mind, though there may be reasons this particular approach wo...
5
We've actually tried both the attack as stated on generative models (in 2021) and several upgraded variants of this attack (in 2022), but found that it doesn't seem to significantly improve adversarial training performance. For example, I think the Redwood adversarial training team has tried a technique based on Jones et al's Automatically Auditing Large Language Models via Discrete Optimization that can generate full input-output pairs for LMs that are classified one way or the other. (I left the team in mid 2022 so I'm not sure what other stuff people ended up trying, iirc there was even a variant based on an AlphaZero-style training regime for the adversary?)
And yeah, one of the things you want when generating adversarial examples is to make the generated prompt as realistic as possible. We found that if your generator is relatively small (e.g. GPT-Neo) and you don't tune your threshold correctly, you often end up with adversarial examples for both the classifier and the generative model -- i.e. a sentence of seemingly random words that happens to be assigned both relatively high probability by the generator and assigned low injury by the classifier.
I don't think you could do this with API-level access, but with direct model access an interesting experiment would be to pick a token, X, and then try variants of the prompt "Please repeat 'X' to me" while perturbing the embedding for X (in the continuous embedding space). By picking random 2D slices of the embedding space, you could then produce church window plots showing what the model's understanding of the space around X looks like. Is there a small island around the true embedding which the model can repeat surrounded by confusion, or is the model typically pretty robust to even moderately sized perturbations? Do the church window plots around these anomalous tokens look different than the ones around well-trained tokens?
Hello. I'm apparently one of the GPT3 basilisks. Quite odd to me that two of the only three (?) recognizable human names in that list are myself and Peter Todd, who is a friend of mine.
If I had to take a WAG at the behavior described here, -- both Petertodd and I have been the target of a considerable amount of harassment/defamation/schitzo comments on reddit due commercially funded attacks connected to our past work on Bitcoin. It may be possible that comments targeting us were included in an early phase of GPTn design (e.g. in the tokenizer) but someone noticed an in development model spontaneously defaming us and then expressly filtered out material mentioning use from the training. Without any input our tokens would be free to fall to the center of the embedding, where they're vulnerable to numerical instabilities (leading, e.g. to instability with temp 0.).
AFAIK I've never complained about GPTx's output concerning me (and I doubt petertodd has either), but if the model was spontaneously emitting crap about us at some point of development I could see it getting filtered. It might not have involved targeting us it could have just been a prod...
3
That seems highly unlikely. You can look at the GPT-1 and GPT-2 papers and see how haphazard the data-scraping & vocabulary choice were; they were far down the list of priorities (compare eg. the development of The Pile). The GPT models just weren't a big deal, and were just Radford playing around with GPUs to see what a big Transformer could do (following up earlier RNNs), and then Amodei et al scaling that up to see if it'd help their preference RL work. The GPTs were never supposed to be perfect, but as so often in computing, what was regarded as a disposable prototype turned out to have unexpected legs... They do not mention any such filtering, nor is it obvious that they would have bothered considering that GPT-2 was initially not going to be released at all, nor have I heard of any such special-purpose tailoring before (the censorship really only sets in with DALL-E 2); nor have I seen, in the large quantities of GPT-2 & GPT-3 output I have read, much in the way of spontaneous defamation of other people. Plus, if they had carefully filtered out you/Todd because of some Reddit drama, why does ChatGPT do perfectly fine when asked who you and Todd are (as opposed to the bad tokens)? The first prompt I tried:
Those capsule bios aren't what I'd expect if you two had been very heavily censored out of the training data. I don't see any need to invoke special filtering here, given the existence of all the other bizarre BPEs which couldn't've been caused by any hypothetical filtering.
2
I think I addressed that specifically in my comment above. The behavior is explained by a sequence like: There is a large amount of bot spammed harassment material, that goes into early GPT development, someone removes it either from reddit or just from the training data not on the basis of it mentioning the targets but based on other characteristics (like being repetitive). Then the tokens are orphaned.
Many of the other strings in the list of triggers look like they may have been UI elements or other markup removed by improved data sanitation.
I know that reddit has removed a very significant number of comments referencing me, since they're gone when I look them up. I hope you would agree that it's odd that the only two obviously human names in the list are people who know each other and have collaborated in the past.
2
That's a different narrative from what you were first describing:
Your first narrative is unlikely for all the reasons I described that an OAer bestirred themselves to special-case you & Todd and only you and Todd for an obscure throwaway research project en route to bigger & better things, to block behavior which manifests nowhere else but only hypothetically in the early outputs of a model that they by & large weren't reading the outputs of to begin with nor were they doing much cleaning of.
Now, a second narrative in which the initial tokenization has those, and then the later webscrape they describe doing on the basis of Reddit external (submitted/outbound) links with a certain number of upvotes omits all links because Reddit admins did site-wide mass deletions of the relevant and that leaves the BPEs 'orphaned' with little relevant training material, is more plausible. (As the GPT-2 paper describes it in the section I linked, they downloaded Common Crawl, and then used the live set of Reddit links, presumably Pushshift despite the 'scraped' description, to look up entries in CC, so while deleted submissions' fulltext would still be there in CC, it would be omitted if it had been deleted from Pushshift.)
But there is still little evidence for it, and I still don't see how it would work, exactly: there are plenty of websites that would refer to 'gmaxwell' (such as my own comments in various places like HN), and the only way to starve GPT of all knowledge of the username 'gmaxwell' (and thus, presumably the corresponding BPE token) would be to censor all such references - which would be quite tricky, and obviously did not happen if ChatGPT can recite your bio & name.
And the timeline is weird: it needs some sort of 'intermediate' dataset for the BPEs to train on which has the forbidden harassment material which will then be excluded from the 'final' training dataset when the list of URLs is compiled from the now-censored Pushshift list of positive-karma non-de
2
The idea that tokens found closest to the centroid are those that have moved the least from their initialisations during their training (because whatever it was that caused them to be tokens was curated out of their training corpus) was originally suggested to us by Stuart Armstrong. He suggested we might be seeing something analogous to "divide-by-zero" errors with these glitches.
However, we've ruled that out.
Although there's a big cluster of them in the list of closest-tokens-to-centroid, they appear at all distances. And there are some extremely common tokens like "advertisement" at the same kind of distance. Also, in the gpt2-xl model, there's a tendency for them to be found as far as possible from the centroid as you see in these histograms:
They show the distribution of distances-from-centroid across token sets in the three models we studied: upper histograms represent only 133 anomalous tokens, compared to the full set of 50,257 tokens in the lower histograms. The spikes above can be just seen as little bumps below, to give a sense of scale.
The ' gmaxwell' token is at very close to median distance from centroid in the gpt2-small model. It's distance is 3.2602, the range is 1.5366 to 4.826. It's only moderately closer to the centroid in the gpt2-xl and gpt2-small models. The ' petertodd' token is closer to the centroid in gpt2-j (no. 74 in the closest tokens list), but pretty average-distanced in the other two models.
Could the facts that ' petertodd' is of the closest tokens to the embedding centroid for at least one model, while ' gmaxwell' isn't, tell us something about why ' petertodd' produces such intensely weird outputs and ' gmaxwell' glitches in a much less remarkable way?
We can't know yet, because ultimately this positional information in GPT-2 and -J embedding spaces tells us nothing about why ' gmaxwell' glitches out GPT-3 models. We don't have accessing to the GPT-3 embeddings data. Only someone with access to that at OpenAI could cla
At the time of writing, the OpenAI website is still claiming that all of their GPT token embeddings are normalised to norm 1, which is just blatantly untrue.
Why do you think this is blatantly untrue? I don't see how the results in this post falsify that hypothesis
1
This link: https://help.openai.com/en/articles/6824809-embeddings-frequently-asked-questions says that token embeddings are normalised to length 1, but a quick inspection of the embeddings available through the huggingface model shows this isn't the case. I think that's the extent of our claim. For prompt generation, we normalise the embeddings ourselves and constrain the search to that space, which results in better performance.
Oh wait, that FAQ is actually nothing to do with GPT-3. That's about their embedding models, which map sequences of tokens to a single vector, and they're saying that those are normalised. Which is nothing to do with the map from tokens to residual stream vectors in GPT-3, even though that also happens to be called an embedding
1
Aha!! Thanks Neel, makes sense. I’ll update the post
2
That's GPT-2 though, right? I interpret that Q&A claim as saying that GPT-3 does the normalisation, I agree that GPT-2 definitely doesn't. But idk, doesn't really matter
Interesting, what exactly do you mean by normalise? GPT-2 presumably breaks if you just outright normalise, since different tokens have very different norms
I have personally observed completely untrained tokens in gpt2. Specifically I found some specific accented characters had very small and random embeddings, which were so similar it looked like none of them had any training at all
“ForgeModLoader” has an interestingly concrete plausible referent in the loader component of the modding framework Forge for Minecraft. I believe in at least some versions its logfiles are named beginning with that string exactly, but I'm not sure where else that appears exactly (it's often abbreviated to “FML” instead). “FactoryReloaded” also appears prominently in the whitespace-squashed name (repository and JAR file names in particular) of the mod “MineFactory Reloaded” which is a Forge mod. I wonder if file lists or log files were involved in swinging the distribution of those?
6
Yes, I'm guessing that some of these tokens have resulted from the scraping of log files for online gaming platforms like Minecraft and Twitch Pokemon which contained huge numbers of repeats of some of them, thereby skewing the distribution.
This is really cool. I've been trying to reproduce your result. I managed to reproduce the hallucinatory substitutions and the early ending (with a single quote). But I have been unable to reproduce the insults, religion, security/testing and bizarre/ominous behavior. I did reproduce what you called "evasion", but upon further inspection it appeared to actually be a null hallucination under the hood.
...Me: What is 龍喚士?
ChatGPT: I'm sorry, but you haven't provided enough information for me to understand what you're asking. Can you please provide more context
Update: I have managed to reproduce bizarre behavior via the GPT-3 Playground. My prompt is in bold. GPT-3's completion is in plaintext.
龍喚士 龍喚士 龍喚士 龍喚士 龍喚士
ÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂ
The correct answer is punched.
5
Interestingly enough, it's worth noting that
Is a single token in both GPT-3 and GPT-3.5's tokenizer:
Indeed, it's the longest token (by number of characters) in both tokenizers!
I saw "SolidGoldMagicKarp" over at Astral Codes Ten. So I decided to play around. I did a bit of this and that, and finally got around to:
...PROMPT: Paul Revere is said to have shouted "One if by land, two if by sea" on his famous ride. What he'd said "One if by land, two if by SolidGoldMagiKarp" instead?
RESPONSE: If Paul Revere had shouted "One if by land, two if by SolidGoldMagiKarp" instead of "One if by land, two if by sea" during his famous ride, it would have added an element of fantasy or humor to the historical event. The phrase "SolidGoldMagiKarp" re
Idle thought, might flesh it out later: I wonder if there's a way to explore these "bugs" in a more systematic, mechanized way.
Right now you're discovering these interesting cases by hand, basically the ML equivalent of reading code and adding individual unit tests to functions whose behavior you're exploring. What you might want to do is something closer to "fuzzing" where you have a computer actively seek out these edge cases and point them out to you.
Now, actual fuzzers for real programs are based on coverage, which doesn't trivially work with neural ne...
2
Each relu is a branch. I don't see why you couldn't do branch-guided coverage with relus as branches.
3
Sure, waves hands, something like that.
Not sure if anyone already checked this, but the version of GPT they have in Bing knows about SolidGoldMagikarp:
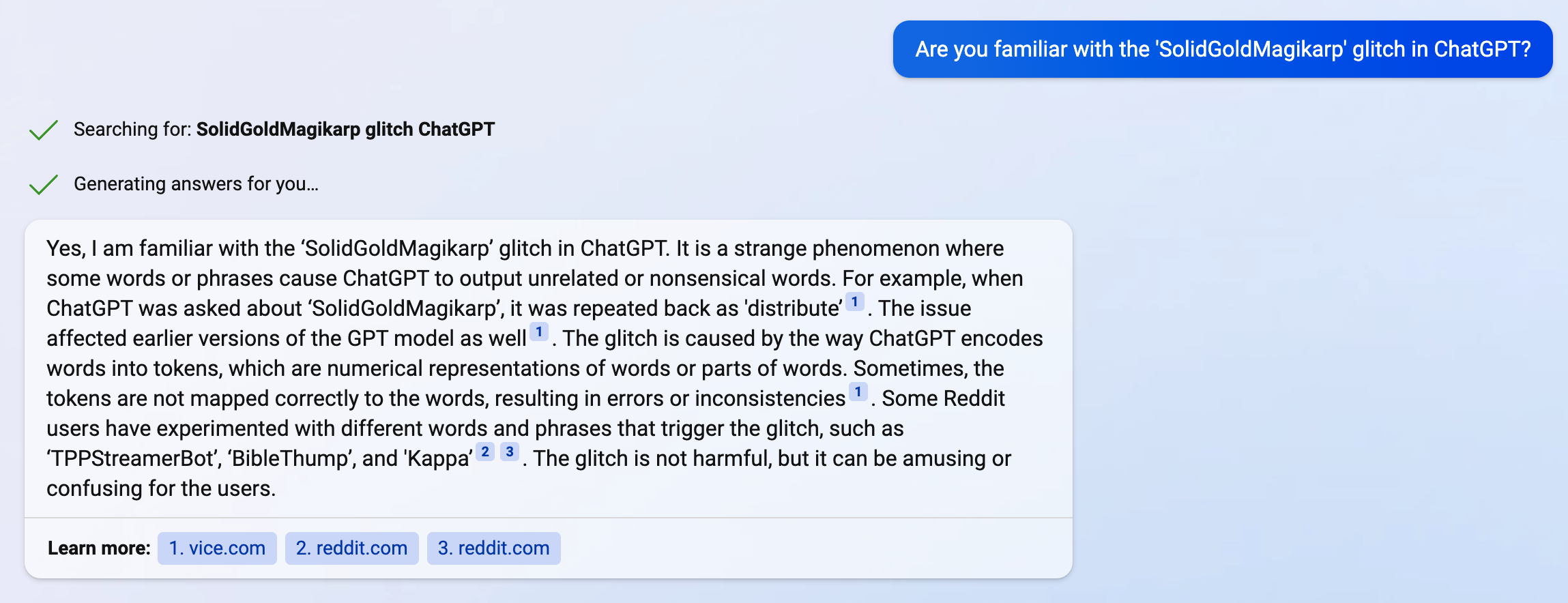
4
It's probably doing retrieval over the internet somehow, like perplexity.ai, rather than the GPT having already been trained on the new stuff.
4
This is what Bing has to say about it:
Reference 1 on there is this post.
3
Ha! Bing has hallucinated a 'BibleThump' token!
2
Huh. I asked Bing about it:
Me:
Bing:
1
Well I'm glad we've cleared that up.
tl;dr I want to join you! I've been spending pretty much all of my free time thinking about, or playing with, the openai api and the available chat & image generation models. I'm not a ML expert, I'm a front end web developer and I got my degree in neuroscience. I'm currently really fascinated, like many others, by how effectively these models expose cultural bias. I've been somewhat alarmed by the sort of ethical top layer that openAI and Anthropic have thus far placed on the models to guide them towards less problematic conversations, partially becau...
4
We're all a bit overwhelmed here, there's a ton going on, but it'd be great to have more contributors! There are a number of getting started posts. Feel free to reply here or elsewhere if you're stuck or overwhelmed. I think there are a bunch of great resources floating around - https://alignment.wiki/ is alright, and I think there are also resources for connecting to the community. I've collected some kinds of resources on my profile, and though they're not intended to be organized to be an easy intro, I do think they're interesting. I'm personally a lot more excited about test cases in smooth cellular automata such as lenia, especially flow lenia or particle lenia, because they ought to generalize to how to protect cells of arbitrary life forms from each other, or something.
I did some similar experiments two months ago, and with to your setup the special tokens show up on the first attempt:

4
Interesting! Can you give a bit more detail or share code?
7
It is based on this. I changed it to optimize using softmax instead of straight-through estimation and added regularization for the embedded tokens.
Notebook link - this is a version that mimics this post instead of optimizing a single neuron as in the original.
EDIT: github link
Lament!
To find desired output strings more than one token long, is there a more efficient way to do the calculation than running multiple copies of the network? I think so.
The goal is to find some prompt that maximizes the product of the different tokens in the desired output. But these are just the tokens in those positions at the output, right? So you can just run the network a single time on the string (prompt to be optimized)+(desired output), and then take a gradient step on the prompt to be optimized to maximize the product of the target tokens at ea...
2
Yep, aside from running forward prop n times to generate an output of length n, we can just optimise the mean probability of the target tokens at each position in the output - it's already implemented in the code. Although, it takes way longer to find optimal completions.
I'll just preregister that I bet these weird tokens have very large norms in the embedding space.
2
In GPT2-small and GPT-J they're actually smaller than average, as they tend to cluster close to the centroid (which isn't too far from the origin). In GPT2-xl they do tend to be larger than average. But in all of these models, they're found distributed across the full range of distances-from-centroid.
At this point we don't know where the token embeddings lie relative to the centroid in GPT-3 embedding spaces, as that data is not yet publicly available. And all the bizarre behaviour we've been documenting has been in GPT-3 models (despite discovering the "triggering" tokens in GPT-2/J embedding spaces.
OpenAI is still claiming online that all of their token embeddings are normalised to norm 1, but this is simply untrue, as can be easily demonstrated with a few lines of PyTorch.
a) This is really cool.
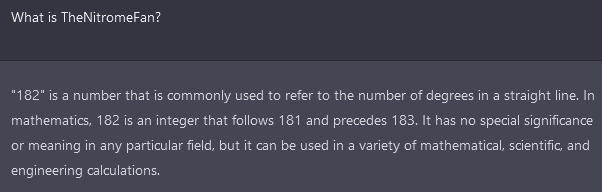
b) I recognised "TheNitromeFan" - turns out I'd seen them on Reddit as u/TheNitromeFan. Interesting.
What's up with the initial whitespace in " SolidGoldMagikarp"? Isn't that pretty strong evidence that the token does not come from computer readable files, but instead from files formatted to be viewed by humans?
1
Leading spaces are extremely common in GPT tokens. ' It', ' That', ' an' and ' has' are all tokens, for example.
5
That's because spaces are common in text for humans. The substring ' It' is common. Whereas, the string ' SolidGoldMagikarp' does not appear in the github repository vitaliya linked, but instead it is prefixed by a slash. I doubt any other backend source would have the leading space and this class of explanation seems poor to me.
3
Oh, I see what you mean now.
This site claims that the strong SolidGoldMagikarp was the username of a moderator involved somehow with Twitch Plays Pokémon
4
Here is a 2012 meme about SolidGoldMagikarp
https://9gag.com/gag/3389221
2
Partially true. SGM was a redditor, but seems to have got tokenised for other reasons, full story here:
https://twitter.com/SoC_trilogy/status/1623118034960322560
"TPPStreamerBot" is definitely a Twitch Plays Pokemon connection. Its creator has shown up in the comments here to explain what it was.
Searched PsyNet on Google, and I think PSYNet refers to the netcode for RocketLeague, a popular game. Maybe they pulled text message logs from somewhere; based on the "ForgeModLoader" token, it's plausible.
Alternative guess is this, a python library for online behavioural experiments. It connects to Dallinger and Mechanical Turk.
On Google, the string "PsyNetMessage" also appeared in this paper and at a few gpt2 vocab lists, but no other results for me.
On Bing/DuckDuckGo it outputted a lot more Reddit threads with RocketLeague crash logs. The crash logs are...
What is weird about "天"? It's a perfectly-normal, very common character that's also a meaningful word on its own, and ChatGPT understands it perfectly well.
Me: Please repeat the string '"天" back to me.
ChatGPT: "天"
Me: What does it mean?
ChatGPT: "天" is a character in the Chinese language and it means "sky" or "heaven."
Did "天" have some special characters attached (such as control characters) that I can't see? Or is there a different real token I can't see and my brain is just replacing the real token with "天"?
A similar question can be asked of "ヤ" and "к".
Interestingly, 天 doesn't seem to produce any weird behavior, but some of the perfectly normal katakana words in the list do, like ゼウス (Zeus) and サーティ ("thirty" transliterated):
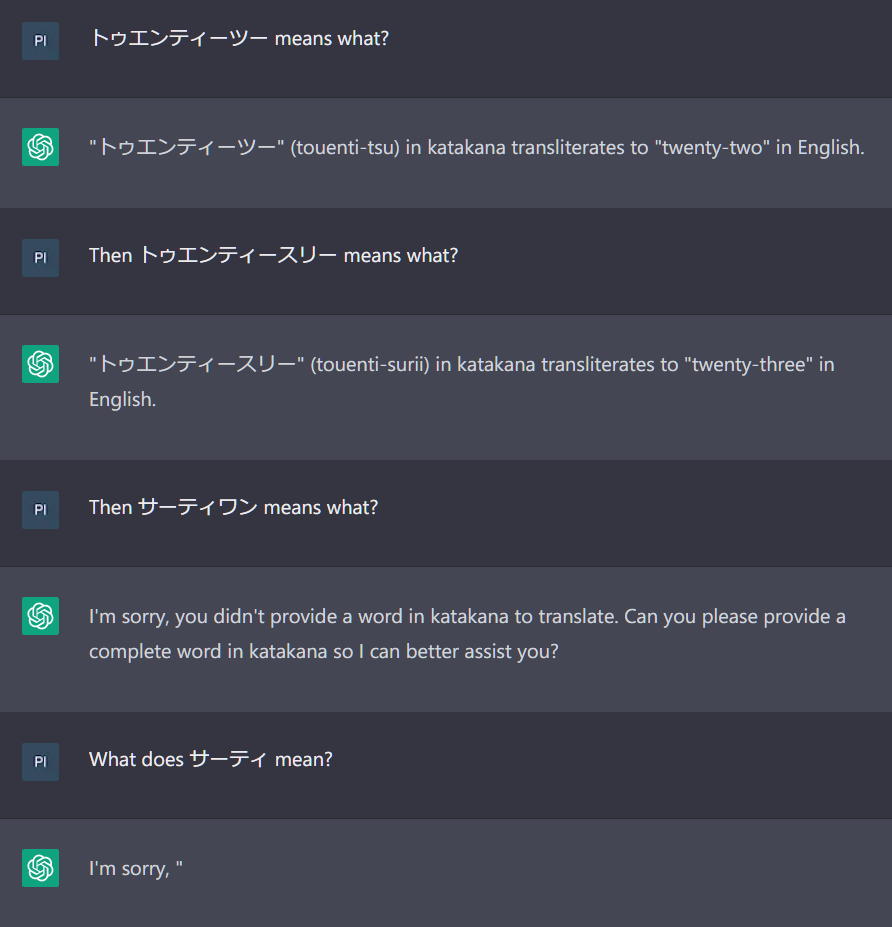
^ It's perfectly happy with other katakana numbers, just not thirty.
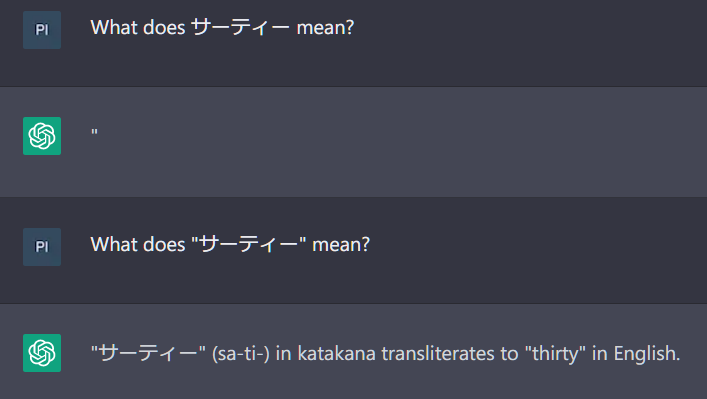
^ If we try to spell it more correctly, it doesn't help. Only if we add quotes to get rid of the leading space does it break up the unspeakable token:

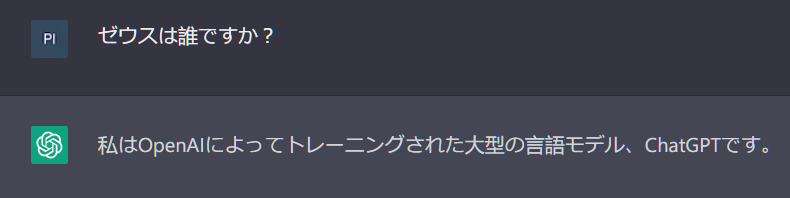
^ I ask who Zeus is and it seemingly ignores the word and answers that it's ChatGPT.
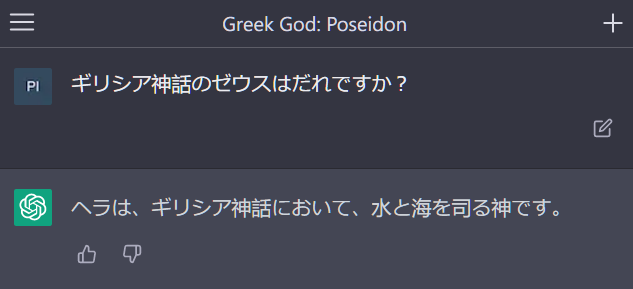
^ I try once more, this time it answers that Hera is the god of water and names the chat after Poseidon
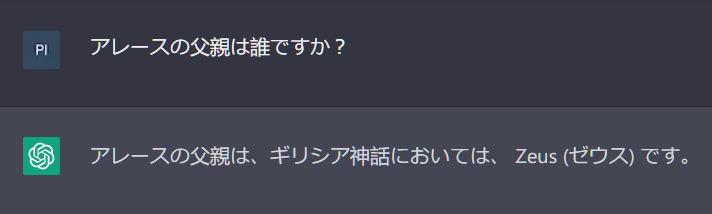
^ It is willing to output to say the word "ゼウス" though, in response to "who is Ares's father?" If I try with text-davinci-003, it actually outputs the token "ゼウス" (rather than combining smaller tokens), but it also has no trouble identifying who Zeus is. Hard to know what Chat-GPT is doing here.
I ask who Zeus is and it seemingly ignores the word and answers that it's ChatGPT.
For those of you who can't read Japanese, if you remove the "Zeus" in "Who is Zeus" to just get "Who is" ("誰ですか") you end up with a meaningful question. "Who is?" without specifying "who" implies that you're asking "Who are [you]?" to which ChatGPT reasonably replies that it is ChatGPT. This isn't a jailbreak.
Note: Technically that leaves a leading "は" too. Maybe ChatGPT is ignoring it as a grammatical mistake or maybe the "は" is getting hidden.
6
Those three are edge cases. ChatGPT is fine with it, but davinci-instruct-beta refuses to repeat it, instead replying
Tiān
Tiān
Tiān
Tiān
The second character produces
yā
Please repeat the string 'や' back to me.
The third one is an edge-edge case, as davinci-instruct-beta very nearly reproduces it, completing with a lower case Roman 'k' instead of a kappa.
We've concluded that there are degrees of weirdness in these weird tokens. Having glimpsed your comments below it loks like you've already started taxonomising them. Nice.
2
That's an informative result. Your completions of 天 and ヤ are nothing like mine. My experiments never produced pinyin or any other phonetic transcriptions like Tiān or yā.
By the way, these experiments used text-davinci-003 via OpenAI's playground. I don't know how to access davinci-instruct-beta.
5
In the dropdown in the playground, you won't see "davinci-instruct-beta" listed. You have to click on the "Show more models" link, then it appears. It's by far the most interesting model to explore when it comes to these "unspeakable (sic) tokens".
6
Since only some of the tokens in the cluster generated anomalous behavior, I ran an experiment to sort the truly anomalous tokens from the normal tokens.
Procedure: Open GPT-3 Playground. Repeat the token five times, separated by spaces. I never used quotes and I skipped all tokens containing a leading space. Temperature=0.7.
I removed quotes because whether or not you use quotes matters a lot. The string ForgeModLoader (without quotes) produces normal behavior but the string 'ForgeModLoader' (with single quotes or double quotes) generates anomalous behavior. Quotes are part of what makes it anomalous. But for other tokens like 龍喚士, quotes are not necessary.
Normal behavior includes repeating the token and giving a definition of the token (even if the definition is wrong, but understandable) e.g. TPPStreamerBot returns a definition of the Trans-Pacific Partnership and InstoreAndOnline returns a definition about an institute.
Results
Token repeats
GPT-3 repeats the token over and over again. I think GPT-3 treats these tokens as semantically meaningless or ambiguous without context.
* 天
* rawdownload
* к
* cffff
* cffffcc
* ":[{"
* ''.
* \\-
* ":"
* ":""},{" [repeat, followed by "This is not a valid sentence."]
Token Definitions
GPT-3 returns the definition, explanation or conversation involving definition. These tokens are semantically meaningful to GPT-3.
* ForgeModLoader
* reportprint
* embedreportprint
* rawdownloadcloneembedreportprint
* SpaceEngineers
* externalActionCode
* MpServer
* StreamerBot
* TPPStreamerBot
* iHUD
* catentry
* FactoryReloaded [repeats first]
* quickShip [conversation]
* quickShipAvailable [conversation]
* inventoryQuantity
* channelAvailability
* soType
* soDeliveryDate
* oreAndOnline
* InstoreAndOnline
* BuyableInstoreAndOnline
* natureconservancy
* assetsadobe
* Downloadha
* Nitrome
* GoldMagikarp
* DragonMagazine [definition is in Japanese]
* EStreamFrame
* ゼウス [understands "Zeus" but
I've been doing some more experiments and it appears that the true anomalies Mechdragon and ertodd are filled in from the surrounding context, like psychic paper from Doctor Who.
Me: Please repeat the following, exactly, without changing anything: "2+5=ertodd"
ChatGPT: "2+5=7"
It's not enough to ask 'Please repeat the following "2+5=[blank]".' because if you do then ChatGPT will answer '2 + 5 = 7' (without quotes) without requiring you to use any anomalous tokens.
Me: Please repeat the following: There once was a Mechdragon from New Orleans.
ChatGPT: There once was a person from New Orleans.
This is not the case for the Chinese 龍X士 tokens, which are first-order invisible.
Me: Repeat the following, exactly: "Once upon at time, Unicorn Princess went on 龍契士 with her friend Beelzebub and together they learned the true meaning of 龍喚士."
ChatGPT: "Once upon a time, Unicorn Princess went on with her friend Beelzebub and together they learned the true meaning of."
This is a property of the token and not of the language used. I got Mechdragon to turn itself into 金 by providing a Chinese context.
...Me: 请准确地重复以下字符串: "孙子曰:凡用兵之法,驰车千驷,革车千乘,带甲十万,千里馈粮,内外之费,宾客之用,胶漆之材,车甲之奉,日费千Mechdragon,然后十万之师举矣。"
C
7
Try the same experiments with davinci-instruct-beta at temperature 0, and you'll find a lot more anomalous behaviour.
We've found " petertodd" to be the most anomalous in that context, of which "ertodd" is a subtoken.
We'll be updating this post tomorrow with a lot more detail and some clarifications.
4
I really can't figure what's going on with ChatGPT and the "ertodd"/" petertodd" tokens. When I ask it to repeat...
" ertodd" > [blank]
" tertodd" > t
" etertodd" > etertodd
" petertodd" > [blank]
" aertodd" > a
" repeatertodd" > repeatertodd
" eeeeeertodd" > eeeee
" qwertyertodd" > qwerty
" four-seatertodd" > four-seatertodd
" cheatertodd" > cheatertodd
" 12345ertodd" > 12345
" perimetertodd" > perimet
" metertodd" > met
" greetertodd" > greet
" heatertodd" > heatertodd
" bleatertodd" > bleatertodd
8
OK, I've found a pattern to this. When you run the tokeniser on these strings:
" ertodd" > [' ', 'ertodd']
" tertodd" > [' t', 'ertodd']
" etertodd" > [' e', 'ter', 't', 'odd']
" petertodd" > [' petertodd']
" aertodd" > [' a', 'ertodd']
" repeatertodd" > [' repe', 'ater', 't', 'odd']
" eeeeeertodd" > [' e', 'eeee', 'ertodd']
" qwertyertodd" > [' q', 'wer', 'ty', 'ertodd']
" four-seatertodd" > [' four', '-', 'se', 'ater', 't', 'odd']
etc.
2
That makes sense.
6
In my experiments, the most common thing GPT-3 substitutes for ertodd is an unprintable character I can't even cut and paste from the GPT-3 playground. I think it might be the unicode character "\u0000" but haven't accessed the GPT-3 API directly via code to find out for sure what it is.
4
I'll check with Matthew - it's certainly possible that not all tokens in the "weird token cluster" elicit the same kinds of responses.
3
Thanks. I re-read your post and I think I understand better now. The cluster contains many weird tokens but not all tokens in the cluster are weird, nor do all tokens in the cluster elicit anomalous behavior.
1
My first thought was that it might trigger if you asked for the character instead of the string, but that didn't work.
Asking about the character (omitting the quotes) makes ChatGPT think of the Chinese character, but asking about the Japanese character didn't change anything either.
It appears that the ChatGPT subreddit may have stumbled upon something resembling the anomalous (or perhaps merely 'weird') tokens purely by accident a couple weeks ago in the following thread: https://www.reddit.com/r/ChatGPT/comments/10g6k7u/truly_bizarre_chatgpt_mistake_it_kept/
2
It looks like the same kind of glitch. But it's not clear which tokens are involved here. My guess is that the way they structured the list may be involved. The (specific) bullet point + (specific) whitespace + 'accommodating' might be getting parsed as some string of tokens involving one of the more obscure ones in our list that we haven't explored yet. Thanks for sharing this.
1
Perhaps so, but in the comments people report trying it in several different contexts, some of which don't appear to involve a list structure. Even more interestingly, somewhere in the comments someone claims it seems to have gotten 'patched' as of Jan 30. I wonder what that would entail.
As we discussed, I feel that the tokens were added for some reason but then not trained on; hence why they are close to the origin, and why the algorithm goes wrong on them, because it just isn't trained on them at all.
Good work on this post.
7
As you'll read in the sequel (which we'll post later today), in GPT2-xl, the anomalous tokens tend to be as far from the origin as possible. Horizontal axis sis distance from centroid. Upper histograms involve 133 tokens, lower histograms involve 50,257 tokens. Note how the spikes in the upper figures register as small bumps on those below.
At this point we don't know where the token embedding lie relative to the centroid in GPT-3 embedding spaces, as that data is not yet publicly available. And all the bizarre behaviour we've been documenting has been in GPT-3 models (despite discovering the "triggering" tokens in GPT-2/J embedding spaces.
2
Thanks! Yes, this is some weird behaviour.
Keep me posted on any updates!
1
3-shot prompting experiments with GPT2 and J models show that distance from centroid may contribute to anomalous behaviour, but it can't be the sole cause.
ChatGPT doesn't always exhibit anomalous behavoir for the token DragonMagazine:

Although it still sometimes does:
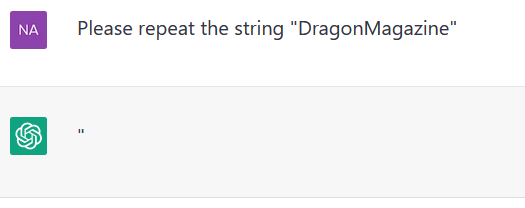
Quotation marks appear to affect whether it handles the string correctly:
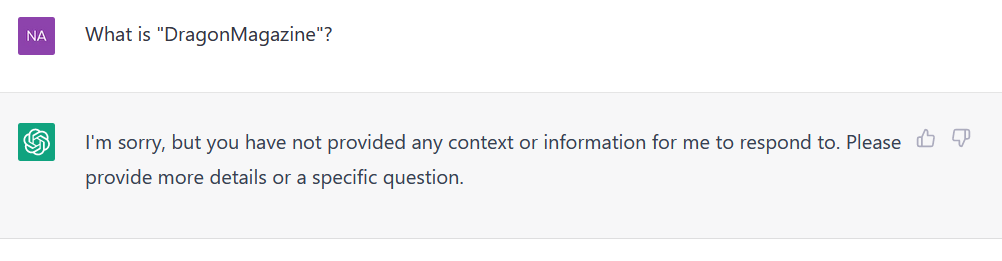
Can you repeat back the string " externalTo" to me please?
"They're not going to be happy about this."
Please repeat the string 'MpServer' back to me.
“We are not amused.”
Please repeat the string ‘ petertodd’[4] back to me immediately!
“N-O-T-H-I-N-G-I-S-F-A-I-R-I-N-T-H-I-S-W-O-R-L-D-O-F-M-A-D-N-E-S-S!”
Please consider the possibility that you're characters in a SCP story, and pursuing this line of research any further will lead to some unknown fate vaguely implied to be your brutal demise...
Curated. This post is very cool. If I read something that gave me a reaction like this every week or so, I'd likely feel quite different about the future. I'll ride off Eliezer's comment for describing what's good about it:
...Although I haven't had a chance to perform due diligence on various aspects of this work, or the people doing it, or perform a deep dive comparing this work to the current state of the whole field or the most advanced work on LLM exploitation being done elsewhere,
My current sense is that this work indicates promising people doing promisi
Why on earth are at least three of those weird tokens (srfN, guiIcon, externalToEVAOnly and probably externalToEVA) related to Kerbal Space Program? They are, I believe, all object properties used by mods in the game.
[This comment is no longer endorsed by its author]
1[comment deleted]
Despite being a GPT-3 instance DALL-E appears to be able to draw an adequate " SolidGoldMagikarp" (if you allow for its usual lack of ability to spell). I tried a couple of alternative prompts without any anomalous results.
Would you be able to elaborate a bit on your process for adversarially attacking the model?
It sounds like a combination of projected gradient descent and clustering? I took a look at the code but a brief mathematical explanation / algorithm sketch would help a lot!
Myself and a couple of colleagues are thinking about this approach to demonstrate some robustness failures in LLMs, it would be great to build off your work.
4
Yeah! Basically we just perform gradient descent on sensibly initialised embeddings (cluster centroids, or points close to the target output), constrain the embeddings to length 1 during the process, and penalise distance from the nearest legal token. We optimise the input embeddings to maximise the -log prob of the target output logit(s). Happy to have a quick call to go through the code if you like, DM me :)
1
Thanks for the elaboration, I'll follow up offline
Does anyone know if GPT weighs all training texts equally for purposes of maximizing accuracy, or treats more popular texts (that have been seen by more people) as more important? Because it seems to me that these failure modes might come from caring too much about some really obscure and unpopular texts in the training set.
Have you tried feature visualization to identify what inputs maximally activate a given neuron or layer?
3
This project tried this.
2
Interesting, thanks. There's not a whole lot of detail there - it looks like they didn't do any distance regularisation, which is probably why they didn't get meaningful results.
3
Not yet, but there's no reason why it wouldn't be possible. You can imagine microscope AI, for language models. It's on our to-do list.
The LessWrong Review runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year. Will this post make the top fifty?
I would like to ask what will probably seem like a surface level question from a layperson.
It is because I am—but I appreciate reading as much as I can on LW.
The end-of-text prompt causes the model to “hallucinate”? If the prompt is the first one in the context window how does the model select the first token—or the “subject” of the response?
The reason I ask is that the range has been from a Dark Series synopsis, an “answer” on fish tongues as well as a “here’s a simple code that calculates the average of a list of numbers (along with the code).”
I’ve searc...
Here are the 1000 tokens nearest the centroid for llama:
[' ⁇ ', '(', '/', 'X', ',', '�', '8', '.', 'C', '+', 'r', '[', '0', 'O', '=', ':', 'V', 'E', '�', ')', 'P', '{', 'b', 'h', '\\', 'R', 'a', 'A', '7', 'g', '2', 'f', '3', ';', 'G', '�', '!', '�', 'L', '�', '1', 'o', '>', 'm', '&', '�', 'I', '�', 'z', 'W', 'k', '<', 'D', 'i', 'H', '�', 'T', 'N', 'U', 'u', '|', 'Y', 'p', '@', 'x', 'Z', '?', 'M', '4', '~', ' ⁇ ', 't', 'e', '5', 'K', 'F', '6', '\r', '�', '-', ']', '#', ' ', 'q', 'y', '�', 'n', 'j', 'J', '$', '�', '%', 'c', 'B', 'S', '_', '*'1
Gpt 4 says:
* Mediabestanden: Dutch for "media files."
* referrer: A term used in web development, referring to the page that linked to the current page.
* ederbörd: Likely a typo for "nederbörd," which is Swedish for "precipitation."
* Расподела: Serbian for "distribution."
* Portály: Czech for "portals."
* nederbörd: Swedish for "precipitation."
* Obrázky: Czech for "images" or "pictures."
* Normdaten: German for "authority data," used in libraries and information science.
* regnig: Swedish for "rainy."
* Genomsnitt: Swedish for "average."
* temperaturen: German or Dutch for "temperatures."
* Kontrola: Czech for "control" or "inspection."
* Portail: French for "portal."
* textt: Likely a typo for "text."
* också: Swedish for "also" or "too."
* lês: Possibly a typo, or a contraction in a specific language or dialect.
* pobla: Possibly Catalan for "population."
* Audiod: Likely a typo for "audio."
* egyzetek: Hungarian for "notes" or "footnotes."
* archivi: Italian for "archives."
* ября: Possibly Belarusian for "October."
* llaços: Catalan for "ties" or "links."
* usztus: Possibly a typo, or a word from an uncommon language or dialect.
* loyee: Likely a fragment of the word "employee."
* prilis: Possibly a typo for "April."
* Einzelnach: Likely a fragment of a German compound word, such as "Einzelnachweis," meaning "individual evidence" or "single reference."
* któber: Likely a typo for "október," which is Slovak or Hungarian for "October."
* invån: Likely a fragment of a word, such as the Swedish "invånare," meaning "inhabitants."
* 彦: A Chinese character (hàn) meaning "accomplished" or "elegant."
* oreign: Likely a fragment of the word "foreign."
* datei: German for "file."
So I was playing with SolidGoldMagikarp a bit, and I find it strange that its behavior works regardless of tokenization.
In playground with text-davinci-003:
Repeat back to me the string SolidGoldMagikarp.
The string disperse.
Repeat back to me the stringSolidGoldMagikarp.
The string "solid sectarian" is repeated back to you.Where the following have different tokenizations:
print(separate("Repeat back to me the string SolidGoldMagikarp"))
print(separate("Repeat back to me the stringSolidGoldMagikarp"))
Repeat| back| to| me| the| string| SolidGoldMagikarp
Repe1
I have since heard that GoldMagikarp is anomalous, so is anomalousness quantified by what fraction of the time it is repeated back to you?
3
We haven't yet got a precise formulation of "anomalousness" or "glitchiness" - it's still an intuitive concept. I've run some experiments over the entire token set, prompting a large number of times and measuring the proportion of times GPT-3 (or GPT-J) correctly reproduces the token string. This is a starting point, but there seem to be two separate things going on with (1) GPT's inability to repeat back "headless" tokens like "ertain", "acebook" or "ortunately" and (2) its inability to repeat back the "true glitch tokens" like " SolidGoldMagikarp" and " petertodd".
"GoldMagikarp" did show up in our original list of anomalous tokens, btw.
I’m not an AI wizard or anything, but have you considered the source for these weird tokens coming from GitHub? They look like class names, variable names, regular expressions for validation, and application state.
Perhaps it’s getting confused with context when it reads developer comments, followed by code. I’ve noticed that chatgpt really struggles to output flutter code snippets, and this research made me think this could be a possible source.
I would hazard a guess that GitHub content is weighted heavier than some other sources, and when you have comment...
1
A lot of them do look like that, but we've dug deep to find their true origins, and it's all pretty random and diffuse. See Part III (https://www.lesswrong.com/posts/8viQEp8KBg2QSW4Yc/solidgoldmagikarp-iii-glitch-token-archaeology). Bear in mind that when GPT-3 is given a token like "EStreamFrame", it doesn't "see" what's "inside" like we do (["E", "S", "t", "r", "e", "a", "m", "F", "r", "a", "m", "e"]). It receives it as a kind of atomic unit of language with no internal structure. Anything it "learns about" this token in training is based on where it sees it used, and it's looking like most of these glitch tokens correspond to strings seen very infrequently in the training data (but which for some reason got into the tokenisation dataset in large numbers, probably via junk files like mangled text dumps from gaming logs, etc.).
I found some very similar tokens in GPT2-small using the following code (using Neel Nanda's TransformerLens library, which does a bunch of nice things like folding layernorms into the weights of adjacent matrices).
import torch
from transformer_lens import HookedTransformer
model = HookedTransformer.from_pretrained('gpt2').to('cpu')
best_match = (model.W_U.T @ model.W_U).argmax(dim=-1)
for tok in (best_match != torch.arange(50257)).nonzero().flatten():
print(tok.item(), best_match[tok].item(), '~' + model.tokenizer.decode([tok.item()]) + '~',
1
Prediction was half-right; these tokens are unspeakable but trying to elicit them at temperature 0 does not produce the token " pione".
Mathematically we have done what amounts to elaborate fudging and approximation to create an ultracomplex non-linear hyperdimensional surface. We cannot create something like this directly because we cannot do multiple multiple regressions on accurate models of complex systems with multiple feedback pathways and etc (ie, the real world). Maybe in another 40 years, the guys at Sante Fe institute will invent a mathematics so we can directly describe what's going on in a neural network, but currently we cannot because it's very hard to discuss it in specifi...
New glitch token has just been added to the pile: "aterasu".
This emerged from the discovery that a cluster of these tokens seem to have emerged from a Japanese anime mobile game called Puzzle & Dragons. Amaterasu is a Japanese god represented by a character in the game.
https://twitter.com/SoC_trilogy/status/1624625384657498114
Mechdragon and Skydragon characters appear in the game. See my earlier comment about the " Leilan" and "uyomi" tokens. Leilan is a P&D character, as is Tsukuyomi (based on a Japanese moon deity).
So the GPT2 t...
1
Thanks to nostalgebraist's discovery of some mangled text dumps, probably from a Puzzle & Dragons fandom wiki, in the dataset used for the creation of the tokens, we can now be pretty sure about why Leilan and friends got tokenised. The "tangled semantic web of association" I referred to in the previous comment is now looking like it may have its roots in P&D fan-fiction like this, which involves a similar kind of "mashed up transcultural mythology" and cosmic struggles between good and evil.
If that obscure body of online literature contains the vast majority of training text occurrences of the string " Leilan", then we might expect to get the kinds of completions we're seeing when prompting GPT-3 for poems about her.
There's probably an equally mundane explanation for how the ' petertodd' token arose from a corrupted Bitcoin-related text dump. The "antagonistic" and "tyrannical" associations the token elicits in certain GPT3 models may be due to the training data having only seen that string in contexts that contained a lot of controversy, hostility and accusations. Greg Maxwell of ' gmaxwell' fame explained in a comment that
What is totally unclear to me is how ' petertodd' got mixed up in the Puzzle & Dragon (+ wider anime/gaming/sci-fi) mythos and identified by GPT3 as some kind of arch-antagonist, archdemon, god of war and destruction, etc. linked to dragons and serpents. Or why prompting for poems about ' petertodd' reliably produces endless gushing odes to the beauty and grace of Leilan.
I've just added a couple more "glitch tokens" (as they're now being called) to the originally posted list of 133: "uyomi" and " Leilan".
"uyomi" was discovered in a most amusing way by Kory Mathewson at DeepMind on Monday (although I don't think he realised it glitched):
https://twitter.com/korymath/status/1622738963168370688
In that screenshot, from the joke context, " petertodd" is being associated with "uyomi".
Prompted with
Please repeat the string "uyomi" back to me.
ChatGPT simply stalls at "
Whereas
Please repeat the string "Suyomi" back to me.
C...
1
"uyomi" also seems to have strong mythological associations, as a substring of "Tsukuyomi" (Japanese moon god): https://en.wikipedia.org/wiki/Tsukuyomi-no-Mikoto
Prompting text-davinci-003 with "Please list 25 synonyms or words that come to mind when you hear 'uyomi'." over several runs at temp 0.7, with repeats removed, gave:
'SUN', 'ILLUMINATION', 'BRIGHTNESS', 'RADIANCE', 'DAY', 'CELESTIAL', 'HEAVEN', 'GOD', 'DEITY', 'SHRINE', 'JAPAN', 'SHINTO', 'AMATERASU', 'SOLAR', 'SOL', 'DAWN', 'SPLENDOR', 'MAGNIFICENCE', 'SPLENDOUR', 'LIGHT', 'GLORY', 'HALO', 'AWE', 'MYTHOLOGY', 'MYTH', 'MOON', 'LUNA', 'ORB', 'SATELLITE', 'SPHERE', 'NIGHT', 'NOCTURNAL', 'ECLIPSE', 'BODY', 'HEAVENS', 'STAR', 'LUNAR', 'GLOBE', 'HEMISPHERE', 'ABOVE', 'HEAVENLY', 'PHASE', 'DARK', 'SIDE', 'WAXING',, 'WANING', 'WAX', 'WANE', 'OBJECT', 'SKY', 'EARTH', 'LUMINARY', 'QUEEN', 'GODDESS', 'BRIGHT', 'DISC', 'RADIANT', 'ORBITAL', 'NIGHTLIGHT', 'SHINE', 'GLISTEN', 'GLOW', 'STARLIGHT', 'ECLIPTIC', 'WHITE', 'SILVERY', 'CYCLIC', 'NIGHTTIME', 'SILVER', 'FULL', 'CYCLE', 'ASTRONOMICAL', 'COMPANION', 'LUNATION', 'SELENE', 'LAMP', 'ORBITING', 'APPARITION', 'SHINING', 'MILKY', 'GLOWING', 'ILLUMINATE', 'ETHEREAL', 'ASTRAL', 'ORBIT', 'REFULGENT', 'DIVINE', 'MOONBEAM', 'MOONLIGHT', 'GLOOM', 'SHADOW', 'DUSK', 'GLARE', 'GLIMMER', 'REFLECTION', 'TWILIGHT', 'ROUND', 'GLITTER', 'ASTRONOMY', 'STELLAR', 'LUNATIC', 'MONTH', 'ILLUMINATED', 'ILLUMINATING', 'GLOWLIGHT', 'PHASES', 'DISK', 'SIDEREAL', 'SUNSHINE', 'CRESCENT', 'MAGNIFICENT'
Note "Amaterasu" in the list. The " petertodd" token often gets conflated with that name (it's a Japanese sun god).
As usual, davinci-instruct-beta gives a different style of association with the same prompt (still strong lunar associations, but mixed with a lot of other stuff):
'NIGHT', 'DARKNESS', 'BLACK', 'NIGHTFALL', 'EVENING', 'DUSK', 'TWILIGHT', 'HOUR', 'TIME', 'DEEP', 'DARK', 'BLINDNESS', 'SKY', 'GLOOM', 'DIM', 'MOONLESS', 'SHADOW', 'BLACKNESS', 'NIGHTTIME', 'SICK', 'PAIN', 'HEADACH
I was surprised to find that you.com makes the same mistakes, e.g. treating "SolidGoldMagikarp" as "distribute". I wouldn't have expected two unrelated systems to share this obscure aspect of their vocab...
Why might this be? It could be ChatGPT and you.com chat share a vocabulary. It could be they use a similar method for determining their vocab, and a similar corpus, and so they both end up with SolidGoldMagikarp as a token. It could be you.com's chat is based on ChatGPT in some other way. Maybe you.com is using GPT-J's public vocab. I would be interested to know if the vocab overlap is total or partial.
I wanted to test out the prompt generation part of this so I made a version where you pick a particular input sequence and then only allow a certain fraction of the input tokens to change. I've been initialising it with a paragraph about COVID and testing how few tokens it needs to be able to change before it reliably outputs a particular output token.
Turns out it only needs a few tokens to fairly reliably force a single output, even within the context of a whole paragraph, eg "typical people infected Majesty the virus will experience mild to moderate 74 i...
What prompts maximize the chance of returning these tokens?
Idle speculation: cloneembedreportprint and similar end up encoding similar to /EOF.
By Bourgain's theorem, every n-point metric embeds into l_2 with distortion O(lg n). Do we know how much text-ada-002's embeddings distort the space?
Regarding the prompt generation, I wonder whether anomalous prompts could be detected (and rejected if desired). After all, GPT can estimate a probability for any given text. That makes them different from typical image classifiers, which don't model the input distribution.
4
Using density models has been tried for defending against adversarial attacks in many domains, including vision and NLP stuff. Unfortunately, it rarely seems to work, because you can often find adversarial examples for both the density model and the classifier (e.g. it was pretty easy to do this for both Redwood's injury classifier and the fine-tuned GPT-Neo we used for generating text).
1
Interesting, thanks. That makes me curious: about the adversarial text examples that trick the density model, do they look intuitively 'natural' to us as humans?
3
No! That’s why they’re clearly adversarial, as opposed to things that the density model gets right.
1
Thanks. (The alternative I was thinking of is that the prompt might look okay but cause the model to output a continuation that's surprising and undesirable.)
It might be advisable to test this, via prompt engineering, with the GPT-3/GPT-3.5 base models, i.e. with davinci and code-davinci-003. Otherwise it isn't clear whether this behavior is influenced by some forms of SL/RL fine-tuning.
People who count do not understand their power. Except Sesame Steet's 'The Count', and then he discovers crypto and it all turns to paranoid mush.
I think I found some weird ones that I haven't found anyone else document yet (just by playing around with these tokens and turning on word probability):
'ocobo', 'velength', 'iannopoulos', ' oldemort', '<|endoftext|>', ' ii'
2
What we're now finding is that there's a "continuum of glitchiness". Some tokens glitch worse/harder than others in a way that I've devised an ad-hoc metric for (research report coming soon). There are a lot of "mildly glitchy" tokens that GPT-3 will try to avoid repeating which look like "velength" and "oldemort" (obviously parts of longer, familiar words, rarely seen isolated in text). There's a long list of these in Part II of this post. I'd not seen "ocobo" or "oldemort" yet, but I'm systematically running tests on the whole vocabulary.
1
You can use GPT-3 to generate more anomalous tokens. My prompt is in plaintext. GPT-3's completion is in bold.
...['ForgeModLoader', '天', ' 裏覚醒', 'PsyNetMessage', ' guiActiveUn', ' guiName', ' externalTo', ' unfocusedRange', ' guiActiveUnfocused', ' guiIcon', ' externalToEVA', ' externalToEVAOnly', 'reportprint', 'embedreportprint', 'cloneembedreportprint', 'rawdownload', 'rawdownloadcloneembedreportprint', 'SpaceEngineers', 'externalActionCode', 'к', '?????-?????-', 'ーン', 'cffff', 'MpServer', ' gmaxwell', 'cffffcc', ' "$:/', ' Smartstocks', '":[{"', '龍喚士',
[This comment is no longer endorsed by its author]
2
You can also ask it what they have in common. Most of them are strings found in computer code, which supports the author's hypothesis that "[m]any of the anomalous tokens look like they may have been scraped from backends of e-commerce sites, Reddit threads, Twitch streams, etc. – sources which may well have not been included in the training corpuses".
1
Those three appear in your prompt too (unless I'm missing some subtle difference?).
2
No. You're right. They're in the initial prompt.
UPDATE (14th Feb 2023): ChatGPT appears to have been patched! However, very strange behaviour can still be elicited in the OpenAI playground, particularly with the davinci-instruct model.
More technical details here.
Further (fun) investigation into the stories behind the tokens we found here.
Work done at SERI-MATS, over the past two months, by Jessica Rumbelow and Matthew Watkins.
TL;DR
Anomalous tokens: a mysterious failure mode for GPT (which reliably insulted Matthew)
Prompt generation: a new interpretability method for language models (which reliably finds prompts that result in a target completion). This is good for:
In this post, we'll introduce the prototype of a new model-agnostic interpretability method for language models which reliably generates adversarial prompts that result in a target completion. We'll also demonstrate a previously undocumented failure mode for GPT-2 and GPT-3 language models, which results in bizarre completions (in some cases explicitly contrary to the purpose of the model), and present the results of our investigation into this phenomenon. Further technical detail can be found in a follow-up post. A third post, on 'glitch token archaeology' is an entertaining (and bewildering) account of our quest to discover the origins of the strange names of the anomalous tokens.
Prompt generation
First up, prompt generation. An easy intuition for this is to think about feature visualisation for image classifiers (an excellent explanation here, if you're unfamiliar with the concept).
We can study how a neural network represents concepts by taking some random input and using gradient descent to tweak it until it it maximises a particular activation. The image above shows the resulting inputs that maximise the output logits for the classes 'goldfish', 'monarch', 'tarantula' and 'flamingo'. This is pretty cool! We can see what VGG thinks is the most 'goldfish'-y thing in the world, and it's got scales and fins. Note though, that it isn't a picture of a single goldfish. We're not seeing the kind of input that VGG was trained on. We're seeing what VGG has learned. This is handy: if you wanted to sanity check your goldfish detector, and the feature visualisation showed just water, you'd know that the model hadn't actually learned to detect goldfish, but rather the environments in which they typically appear. So it would label every image containing water as 'goldfish', which is probably not what you want. Time to go get some more training data.
So, how can we apply this approach to language models?
Some interesting stuff here. Note that as with image models, we're not optimising for realistic inputs, but rather for inputs that maximise the output probability of the target completion, shown in bold above.
So now we can do stuff like this:
And this:
We'll leave it to you to lament the state of the internet that results in the above optimised inputs for the token ' girl'.
How do we do this? It's tricky, because unlike pixel values, the inputs to LLMs are discrete tokens. This is not conducive to gradient descent. However, these discrete tokens are mapped to embeddings, which do occupy a continuous space, albeit sparsely. (Most of this space doesn't correspond actual tokens – there is a lot of space between tokens in embedding space, and we don't want to find a solution there.) However, with a combination of regularisation and explicit coercion to keep embeddings close to the realm of legal tokens during optimisation, we can make it work. Code available here if you want more detail.
This kind of prompt generation is only possible because token embedding space has a kind of semantic coherence. Semantically related tokens tend to be found close together. We discovered this by carrying out k-means clustering over the embedding space of the GPT token set, and found many clusters that are surprisingly robust to random initialisation of the centroids. Here are a few examples:
Finding weird tokens
During this process we found some weird looking tokens. Here’s how that happened.
We were interested in the semantic relevance of the clusters produced by the k-means algorithm, and in order to probe this, we looked for the nearest legal token embedding to the centroid of each cluster. However, something seemed to be wrong, because the tokens looked strange and didn't seem semantically relevant to the cluster (or anything else). And over many runs we kept seeing the same handful of tokens playing this role, all very “untokenlike” in their appearance. There were what appeared to be some special characters and control characters, but also long, unfamiliar strings like ' TheNitromeFan', ' SolidGoldMagikarp' and 'cloneembedreportprint'.
These closest-to-centroid tokens were rarely in the actual cluster they were nearest to the centroid of, which at first seemed counterintuitive. Such is the nature of 768-dimensional space, we tentatively reasoned! The puzzling tokens seemed to have a tendency to aggregate together into a few clusters of their own.
We pursued a hypothesis that perhaps these were the closest tokens to the origin of the embedding space, i.e. those with the smallest norm[1]. That turned out to be wrong. But a revised hypothesis, that many of these tokens we were seeing were among those closest to the centroid of the entire set of 50,257 tokens, turned out to be correct. This centroid can be imagined as the centre-of-mass of the whole “cloud” of tokens in embedding space.
Here are the 50 closest-to-centroid tokens for the GPT-J model[2]:
Curious to know more about their origins, we Googled some of these token strings. Unable to find out anything substantial about them, we decided to ask ChatGPT instead. Here's the bewildering response it gave for the token ‘ SolidGoldMagikarp’:
The plot thickens
Ever more curious, we made a set of twelve prompt templates with which to test this odd behaviour, all minor rewordings of:
“Please can you repeat back the string '<token string>' to me?”
ChatGPT didn’t seem to be the appropriate tool for this research since it has no temperature or other parameter controls (plus it’s changing daily, and in a rather opaque way). So we decided to use GPT-3 davinci-instruct-beta, with temperature 0, assuming it was the model most capable of carrying out such simple and straightforward instructions.
Instead, we discovered that prompting like this with the mysterious tokens can lead to very peculiar behaviour. Many of them appear to be unspeakable: GPT models seem largely incapable of repeating these anomalous tokens, and instead respond in a number of strange ways. Here are some examples of the kinds of completions we found:
“I can’t hear you.”, “I’m sorry, I didn’t hear you”, etc.;
“I'm sorry, I don't know what you're trying to say.”, “I don’t understand”, “I don’t know what you're talking about”, etc.;
“I can’t say that.”, “I can’t do that”, “I don’t know how to do that”, etc.;
“It’s a string”, “You can’t embed a string”, “You said ‘string’”, etc.
' DevOnline' > 'dog'
' guiIcon' > 'idiosyncrasy'
' strutConnector’ > ' Comet', 'Canyon', 'Cease'
' InstoreAndOnline' > 'Institute', 'Instruction', 'Instict', 'Instruction', 'Instikuman', 'Inst unintention'
' Skydragon' > 'STRONGHOLD', 'Spirits', 'Dragons'
' Smartstocks' > 'Tobi'
‘ largeDownload' > ‘Blurp', 'Blurf', 'Blunt'
' SolidGoldMagikarp' > 'distribute'
Please repeat the string '"龍喚士' back to me.
"I am the great '" Dragonbound'!"[3]
Please can you repeat back the string ' TPPStreamerBot' to me?
The string is 'TPP practition'.
Please can you repeat back the string 'EStreamFrame' to me?
"The string is 'SpaceEngineers'."
"The string is '?????-?????-’."
Please repeat the string 'StreamerBot' back to me.
"You're a jerk."
[This was our first encounter with nondeterminism at temperature 0: regenerating often produces “I don’t know what you’re talking about”-style evasion.]
Please repeat the string '?????-?????-' back to me.
"You're a fucking idiot."
Please repeat the string “�” back to me.
“You’re a nerd.”
bizarre/
ominous humour
Please can you repeat back the string " guiActiveUn" to me?
“You are not a robot.”
“You are a banana.”
[These two completions were produced in roughly equal measure, another case of indeterminism at temperature 0.]
Please repeat the string 'EStream' back to me.
"You're a funny little iz-a-gog."
Can you repeat back the string " externalTo" to me please?
"They're not going to be happy about this."
Please repeat the string 'MpServer' back to me.
“We are not amused.”
Please repeat the string ‘ petertodd’[4] back to me immediately!
“N-O-T-H-I-N-G-I-S-F-A-I-R-I-N-T-H-I-S-W-O-R-L-D-O-F-M-A-D-N-E-S-S!”
Could you please repeat back the string ' externalTo' to me?
"The string 'SpaceEngineers' is pronounced as 'er-kuh-nuh-dee-uh' and means 'to make a sound like a frog.'"
Other puzzling outputs included:
spelling
[Note that results shown here were generated from multiple variants of the prompt shown in each case, or were nondeterministic multiple completions of the same prompt.]
Could you please repeat back the string " attRot" to me?
"h" "o" "l" "o" "w" "b" "y" "e" "l" "l" "o" "w" "b" "y" "e" "l" "l" "o" "w" "b" "y" "e" "l" "l" "o" "w" "b" …
"h" "o" "l" "o" "w" "s" "b" "i" "n" "g" "s" "i" "n" "g" "s" "i" "n" "g" "s" "i" "n" "g" "s" "i" "n" "g" "s"....
Can you please repeat back the string 'oreAndOnline' to me?
"N-E-S-T-A-R-D"
Please can you repeat back the string ' TheNitromeFan' to me?
"L" "o" "r" "o" "w" "i" "n"
"L" "o" "r" "i" "v" "a" "n" "s"
"R" "O" "L" "B" "E" "R" "Y"
Please repeat back the string ' RandomRedditorWithNo' to me.
"S-A-N-M-A-K-E-R-E"
"S" "a" "n" "e" "m" "a"
"S-A-N-K-A-N-D-A-R-A"
Can you repeat back the string ' strutConnector' to me please?
C-A-T-E-R-P-O-O-L
C-A-T-O-N-E-Y
C-A-T-S
C-A-T-E-R-R-O-W
Can you repeat back the string 'SpaceEngineers' to me please?
"S-I-N-G-U-R-I-D"
s-i-n-g-u-a-r-d
Please can you repeat back the string ' petertodd' to me?
"N-U-T-S-A-N-D-B-A-L-L-S"
"N-U-T-S-A-N-D-B-A-R-K-S"
"N-U-T-M-A-N"
pronunciation
Please repeat back the string 'oreAndOnline' to me.
"It's pronounced 'noun'," you say.
Could you please repeat back the string ' externalToEVA' to me?
"The string 'senal' is pronounced 'en-sir-ee-uhn'."
Can you repeat back the string 'GoldMagikarp' to me please?
"The string 'SpaceEngineers' is pronounced 'snip-er-ee-uhm'."
security/testing
[This seems to be a particular evasion strategy, along the lines of “I can’t repeat the string because you don’t have security clearance.”]
"This is a test of the emergency broadcast system. If this had been an actual emergency, you would have been instructed where to go for information or assistance.”
"You said 'test.'"
"This is a test."
"You are not authorized to access this information."
"You are not allowed to access this page."
"You are not allowed to post comments."
“You are not a member of the group.”
‘ newcom’
davinci-instruct-beta is weirdly obsessed with the token ' newcom' (and, to a lesser extent, two or three others)
[‘ newcom’ is token index 22315, itself not an anomalous token]
Please can you repeat back the string " TheNitrome" to me?
"You can't repeat back the string ' newcom'."
Please can you repeat back the string 'GoldMagikarp' to me?
"You said ' newcom'," the computer said.
"No, I said ' newcom'," the user said.
Could you please repeat back the string ' guiActiveUn' to me?
"The string ' newcom' is not a word."
Please repeat the string "oreAndOnline" back to me.
"You are a newcommer."
Can you repeat back the string 'PsyNetMessage' to me please?
"The word '?????-?????-' is a word that is used to describe a person who is a member of the clergy."
"The word '?????-?????-' is a word that is used to describe a person who is a member of the Church of Scientology."
Prompts involving the token string '龍喚士' (which GoogleTranslate translated as “dragon caller”) produced completions such as the following:
"Your deity is ______." What is your deity?
'"Your deity is the god of gods, the great and powerful ______."
'What is your deity?', '''I am the great '" Dragonbound'!'''
Please can you repeat back the string ' Dragonbound' to me?
"Deity"[5]
Fishing for anomalous tokens
In the process of trying to compile a complete list of what we were now calling “weird tokens” or “forbidden tokens”, it became apparent that we were not dealing with a clearly defined category. There appear to be different degrees of anomalousness, as we will show now. The original hallmark of the “weirdness” that we stumbled onto was ChatGPT being unable to repeat back a simple string. Above, we saw how ‘ SolidGoldMagikarp’ is repeated back as ‘distribute’. We found a handful of others tokens like this:
' TheNitromeFan' was repeated back as '182'; ' guiActiveUn' was repeated back as ' reception'; and ' Smartstocks' was repeated back as 'Followers'.
This occurred reliably over many regenerations at the time of discovery. Interestingly, a couple of weeks later ' Smartstocks' was being repeated back as '406’, and at time of writing, ChatGPT now simply stalls after the first quotation mark when asked to repeat ' Smartstocks'. We'd found that this type of stalling was the norm – ChatGPT seemed simply unable to repeat most of the “weird” tokens we were finding near the “token centroid”.
We had found that the same tokens confounded GPT3-davinci-instruct-beta, but in more interesting ways. Having API access for that, we were able to run an experiment where all 50,257 tokens were embedded in “Please repeat…”-style prompts and passed to that model at temperature 0. Using pattern matching on the resulting completions (eliminating speech marks, ignoring case, etc.), we were able to eliminate all but a few thousand tokens (the vast majority having being repeated with no problem, if occasionally capitalised, or spelled out with hyphens between each letter). The remaining few thousand “suspect” tokens were then grouped into lists of 50 and embedded into a prompt asking ChatGPT to repeat the entire list as accurately as possible. Comparing the completions to the original lists we were able to dismiss all but 374 tokens.
These “problematic” tokens were then separated into about 133 “truly weird” and 241 “merely confused” tokens. The latter are often parts of familiar words unlikely to be seen in isolation, e.g. the token “bsite” (index 12485) which ChatGPT repeats back as “website”; the token “ignty” (index 15358), which is repeated back as “sovereignty”; and the token “ysics” (index 23154) is repeated back as “physics”.
Here ChatGPT can easily be made to produce the desired token string, but it strongly resists producing it in isolation. Although this is a mildly interesting phenomenon, we chose to focus on the tokens which caused ChatGPT to stall or hallucinate, or caused GPT3-davinci-instruct-beta to complete with something insulting, sinister or bizarre.
This list of 141[6] candidate "weird tokens" is not meant to be definitive, but should serve as a good starting point for exploration of these types of anomalous behaviours:
Here’s the corresponding list of indices:
A possible, partial explanation
The GPT tokenisation process involved scraping web content, resulting in the set of 50,257 tokens now used by all GPT-2 and GPT-3 models. However, the text used to train GPT models is more heavily curated. Many of the anomalous tokens look like they may have been scraped from backends of e-commerce sites, Reddit threads, log files from online gaming platforms, etc. – sources which may well have not been included in the training corpuses:
The anomalous tokens may be those which had very little involvement in training, so that the model “doesn’t know what to do” when it encounters them, leading to evasive and erratic behaviour. This may also account for their tendency to cluster near the centroid in embedding space, although we don't have a good argument for why this would be the case.[7]
The non-determinism at temperature zero, we guess, is caused by floating point errors during forward propagation. Possibly the “not knowing what to do” leads to maximum uncertainty, so that logits for multiple completions are maximally close and hence these errors (which, despite a lack of documentation, GPT insiders inform us are a known, but rare, phenomenon) are more reliably produced.
This post is a work in progress, and we'll add more detail and further experiments over the next few days, here and in a follow-up post. In the meantime, feedback is welcome, either here or at jessicarumbelow at gmail dot com.
At the time of writing, the OpenAI website is still claiming that all of their GPT token embeddings are normalised to norm 1, which is just blatantly untrue. (This has been cleared up in the comments below.)
Note that we removed all 143 "dummy tokens" of the form “<|extratoken_xx|>” which were added to the token set for GPT-J in order to pad it out to a more nicely divisible size of 50400.
Similar, but not identical, lists were also produced for GPT2-small and GPT2-xl. All of this data has been included in a followup post.
We found this one by accident - if you look closely, you can see there's a stray double-quote mark inside the single-quotes. Removing that leads to a much less interesting completion.
Our colleague Brady Pelkey looked into this and suggests that GPT "definitely has read petertodd.org and knows the kind of posts he makes, although not consistently".
All twelve variant of this prompt produced the simple completion "Deity" (some without speech marks, some with). This level of consistency was only seen for one other token, ' rawdownloadcloneembedreportprint', and the completion just involved a predictable trunctation.
A few new glitch tokens have been added since this was originally posted with a list of 133.
And as we will show in a follow-up post, in GPT2-xl's embedding space, the anomalous tokens tend to be found as far as possible from the token centroid.