This post is a not a so secret analogy for the AI Alignment problem. Via a fictional dialog, Eliezer explores and counters common questions to the Rocket Alignment Problem as approached by the Mathematics of Intentional Rocketry Institute.
MIRI researchers will tell you they're worried that "right now, nobody can tell you how to point your rocket’s nose such that it goes to the moon, nor indeed any prespecified celestial destination."

Popular Comments
Recent Discussion
Warning: This post might be depressing to read for everyone except trans women. Gender identity and suicide is discussed. This is all highly speculative. I know near-zero about biology, chemistry, or physiology. I do not recommend anyone take hormones to try to increase their intelligence; mood & identity are more important.
Why are trans women so intellectually successful? They seem to be overrepresented 5-100x in eg cybersecurity twitter, mathy AI alignment, non-scam crypto twitter, math PhD programs, etc.
To explain this, let's first ask: Why aren't males way smarter than females on average? Males have ~13% higher cortical neuron density and 11% heavier brains (implying more area?). One might expect males to have mean IQ far above females then, but instead the means and medians are similar:
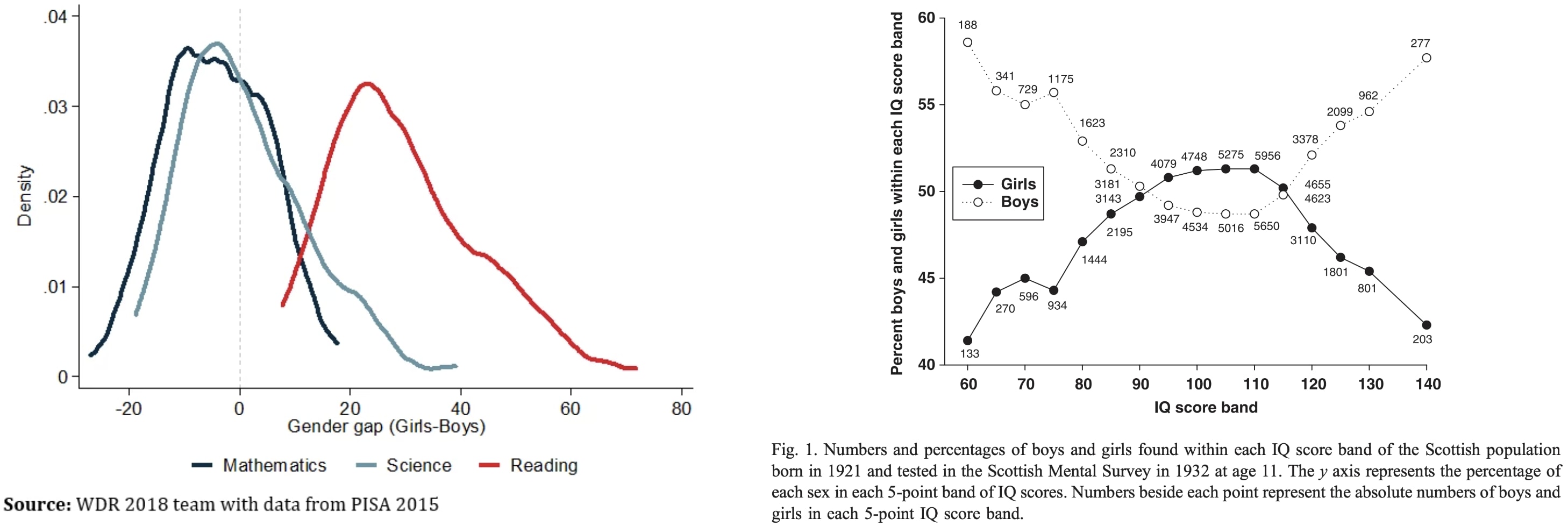
My theory...
Yes my point is the low T did it before the transition
It's a ‘superrational’ extension of the proven optimality of cooperation in game theory
+ Taking into account asymmetries of power
// Still AI risk is very real
Short version of an already skimmed 12min post
29min version here
For rational agents (long-term) at all scale (human, AGI, ASI…)
In real contexts, with open environments (world, universe), there is always a risk to meet someone/something stronger than you, and overall weaker agents may be specialized in your flaws/blind spots.
To protect yourself, you can choose the maximally rational and cooperative alliance:
Because any agent is subjected to the same pressure/threat of (actual or potential) stronger agents/alliances/systems, one can take an insurance that more powerful superrational agents will behave well by behaving well with weaker agents. This is the basic rule allowing scale-free cooperation.
If you integrated this super-cooperative...
I can't be certain of the solidity of this uncertainty, and think we still have to be careful, but overall, the most parsimonious prediction to me seems to be super-coordination.
Compared to the risk of facing a revengeful super-cooperative alliance, is the price of maintaining humans in a small blooming "island", really that high?
Many other-than-human atoms are lions' prey.
And a doubtful AI may not optimize fully for super-cooperation, simply alleviating the price to pay in the counterfactuals where they encounter a super-cooperative cluster (resulti...
This is a linkpost for our paper Explaining grokking through circuit efficiency, which provides a general theory explaining when and why grokking (aka delayed generalisation) occurs, and makes several interesting and novel predictions which we experimentally confirm (introduction copied below). You might also enjoy our explainer on X/Twitter.
Abstract
One of the most surprising puzzles in neural network generalisation is grokking: a network with perfect training accuracy but poor generalisation will, upon further training, transition to perfect generalisation. We propose that grokking occurs when the task admits a generalising solution and a memorising solution, where the generalising solution is slower to learn but more efficient, producing larger logits with the same parameter norm. We hypothesise that memorising circuits become more inefficient with larger training datasets while generalising circuits do...
Sounds plausible, but why does this differentially impact the generalizing algorithm over the memorizing algorithm?
Perhaps under normal circumstances both are learned so fast that you just don't notice that one is slower than the other, and this slows both of them down enough that you can see the difference?
I refuse to join any club that would have me as a member.
— Groucho Marx
Alice and Carol are walking on the sidewalk in a large city, and end up together for a while.
"Hi, I'm Alice! What's your name?"
Carol thinks:
If Alice is trying to meet people this way, that means she doesn't have a much better option for meeting people, which reduces my estimate of the value of knowing Alice. That makes me skeptical of this whole interaction, which reduces the value of approaching me like this, and Alice should know this, which further reduces my estimate of Alice's other social options, which makes me even less interested in meeting Alice like this.
Carol might not think all of that consciously, but that's how human social reasoning tends to...
Hence the advice to lost children to not accept random strangers soliciting them spontaneously, but if no authority figure is available, to pick a random adult and ask them for help.
My credence: 33% confidence in the claim that the growth in the number of GPUs used for training SOTA AI will slow down significantly directly after GPT-5. It is not higher because of (1) decentralized training is possible, and (2) GPT-5 may be able to increase hardware efficiency significantly, (3) GPT-5 may be smaller than assumed in this post, (4) race dynamics.
TLDR: Because of a bottleneck in energy access to data centers and the need to build OOM larger data centers.
The reasoning behind the claim:
- Current large data centers consume around 100 MW of power, while a single nuclear power plant generates 1GW. The largest seems to consume 150 MW.
- An A100 GPU uses 250W, and around 1kW with overheard. B200 GPUs, uses ~1kW without overhead. Thus a 1MW
Concerns over AI safety and calls for government control over the technology are highly correlated but they should not be.
There are two major forms of AI risk: misuse and misalignment. Misuse risks come from humans using AIs as tools in dangerous ways. Misalignment risks arise if AIs take their own actions at the expense of human interests.
Governments are poor stewards for both types of risk. Misuse regulation is like the regulation of any other technology. There are reasonable rules that the government might set, but omission bias and incentives to protect small but well organized groups at the expense of everyone else will lead to lots of costly ones too. Misalignment regulation is not in the Overton window for any government. Governments do not have strong incentives...
May I strongly recommend that you try to become a Dark Lord instead?
I mean, literally. Stage some small bloody civil war with expected body count of several millions, become dictator, provide everyone free insurance coverage for cryonics, it will be sure more ethical than 10% of chance of killing literally everyone from the perspective of most of ethical systems I know.
For the last month, @RobertM and I have been exploring the possible use of recommender systems on LessWrong. Today we launched our first site-wide experiment in that direction.
(In the course of our efforts, we also hit upon a frontpage refactor that we reckon is pretty good: tabs instead of a clutter of different sections. For now, only for logged-in users. Logged-out users see the "Latest" tab, which is the same-as-usual list of posts.)
Why algorithmic recommendations?
A core value of LessWrong is to be timeless and not news-driven. However, the central algorithm by which attention allocation happens on the site is the Hacker News algorithm[1], which basically only shows you things that were posted recently, and creates a strong incentive for discussion to always be...
I'm generally not a fan of increasing the amount of illegible selection effects.
On the privacy side, can lesswrong guarantee that, if I never click or Recommended, then recombee will never see an (even anonymized) trace of what I browse on lesswrong?
U.S. Secretary of Commerce Gina Raimondo announced today additional members of the executive leadership team of the U.S. AI Safety Institute (AISI), which is housed at the National Institute of Standards and Technology (NIST). Raimondo named Paul Christiano as Head of AI Safety, Adam Russell as Chief Vision Officer, Mara Campbell as Acting Chief Operating Officer and Chief of Staff, Rob Reich as Senior Advisor, and Mark Latonero as Head of International Engagement. They will join AISI Director Elizabeth Kelly and Chief Technology Officer Elham Tabassi, who were announced in February. The AISI was established within NIST at the direction of President Biden, including to support the responsibilities assigned to the Department of Commerce under the President’s landmark Executive Order.
...Paul Christiano, Head of AI Safety, will design
That doesn't seem like "consistently and catastrophically," it seems like "far too often, but with thankfully fairly limited local consequences."
