This post is a not a so secret analogy for the AI Alignment problem. Via a fictional dialog, Eliezer explores and counters common questions to the Rocket Alignment Problem as approached by the Mathematics of Intentional Rocketry Institute.
MIRI researchers will tell you they're worried that "right now, nobody can tell you how to point your rocket’s nose such that it goes to the moon, nor indeed any prespecified celestial destination."

Popular Comments
Recent Discussion
This is a Concept Post. It may not be worth reading on its own, out of context. See the backlinks at the bottom to see which posts use this concept.
See the backlinks at the bottom of the post. Every post starting with [CP] is a concept post, that describes a concept this post is using.
Problem: Often when writing I come up with general concepts that make sense in isolation. Often I want to reuse these concepts without having to reexplain them.
A Concept Post is explaining a single concept, usually with no or minimal context. It is expected that the relevant context is provided by another post that links to the concept post.
Concept Posts can be very short. Much shorter than a regular post. They might not be worth reading on their own. Therefore the notice at the top...
Adopted.
Nevertheless lots of people were hassled. That has real costs, both to them and to you.
For the last month, @RobertM and I have been exploring the possible use of recommender systems on LessWrong. Today we launched our first site-wide experiment in that direction.
(In the course of our efforts, we also hit upon a frontpage refactor that we reckon is pretty good: tabs instead of a clutter of different sections. For now, only for logged-in users. Logged-out users see the "Latest" tab, which is the same-as-usual list of posts.)
Why algorithmic recommendations?
A core value of LessWrong is to be timeless and not news-driven. However, the central algorithm by which attention allocation happens on the site is the Hacker News algorithm[1], which basically only shows you things that were posted recently, and creates a strong incentive for discussion to always be...
drat, I was hoping that one would work. oh well. yes, I use ublock, as should everyone. Have you considered simply not having analytics at all :P I feel like it would be nice to do the thing that everyone ought to do anyway since you're in charge. If I was running a website I'd simply not use analytics.
back to the topic at hand, I think you should just make a vector embedding of all posts and show a HuMAP layout of it on the homepage. that would be fun and not require sending data anywhere. you could show the topic islands and stuff.
The history of science has tons of examples of the same thing being discovered multiple time independently; wikipedia has a whole list of examples here. If your goal in studying the history of science is to extract the predictable/overdetermined component of humanity's trajectory, then it makes sense to focus on such examples.
But if your goal is to achieve high counterfactual impact in your own research, then you should probably draw inspiration from the opposite: "singular" discoveries, i.e. discoveries which nobody else was anywhere close to figuring out. After all, if someone else would have figured it out shortly after anyways, then the discovery probably wasn't very counterfactually impactful.
Alas, nobody seems to have made a list of highly counterfactual scientific discoveries, to complement wikipedia's list of multiple discoveries.
To...
Lucius-Alexander SLT dialogue?
Before we get started, this is your quarterly reminder that I have no medical credentials and my highest academic credential is a BA in a different part of biology (with a double major in computer science). In a world with a functional medical system no one would listen to me.
Tl;dr povidone iodine probably reduces viral load when used in the mouth or nose, with corresponding decreases in symptoms and infectivity. The effect size could be as high as 90% for prophylactic use (and as low as 0% when used in late illness), but is probably much smaller. There is a long tail of side-effects. No study I read reported side effects at clinically significant levels, but I don’t think they looked hard enough. There are other gargle...
Yep that's my main contender for the better formulations referred to in the intro. .
This is a Concept Post. It may not be worth reading on its own, out of context. See the backlinks at the bottom to see which posts use this concept.
Also known as periodically labeled lattice graphs in graph theory.
Here is a concrete Edge Regular Lattice Graph:
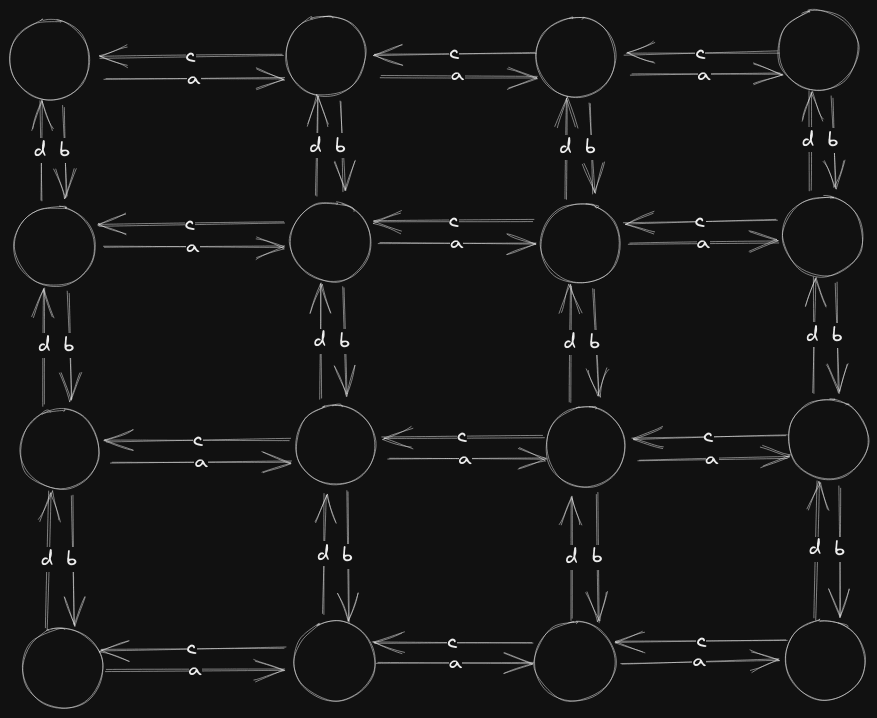
In this graph, the following pattern is repeating locally:
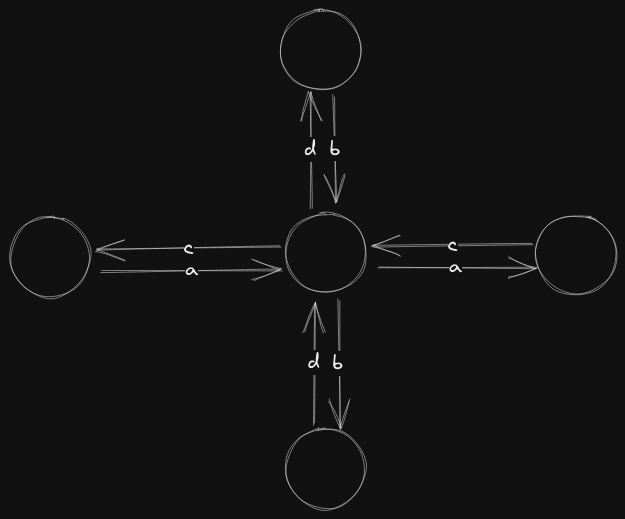
So a Edge Regular Lattice Graph is a Lattice graph , such that in the natural embedding of , each edge label points in the same direction from the perspective of every vertex. Also, the number of edge labels is twice the number of dimensions.
Above we have 4 edge labels in the 2D lattice graph. One for each direction. In a 3D lattice graph, we would have 6 edge labels.
OC ACXLW Sat April 27 Argumentation and College Admissions
Hello Folks! We are excited to announce the 63rd Orange County ACX/LW meetup, happening this Saturday and most Saturdays after that.
Host: Michael Michalchik Email: michaelmichalchik@gmail.com (For questions or requests) Location: 1970 Port Laurent Place (949) 375-2045 Date: Saturday, April 27 2024 Time 2 pm
Conversation Starters:
- You Can Make an Argument for Anything by Nathan J. Robinson: This article argues that it is easy to create superficially convincing arguments for almost any position, no matter how heinous or false. The author suggests that the prevalence of these arguments can make it difficult for the truth to compete in the "marketplace of ideas."
Text link: https://www.currentaffairs.org/2018/11/you-can-make-an-argument-for-anything
Questions for discussion: a) The article suggests that people often do not investigate arguments very closely, and are...
TL;DR All GPT-3 models were decommissioned by OpenAI in early January. I present some examples of ongoing interpretability research which would benefit from the organisation rethinking this decision and providing some kind of ongoing research access. This also serves as a review of work I did in 2023 and how it progressed from the original ' SolidGoldMagikarp' discovery just over a year ago into much stranger territory.
Introduction
Some months ago, when OpenAI announced that the decommissioning of all GPT-3 models was to occur on 2024-01-04, I decided I would take some time in the days before that to revisit some of my "glitch token" work from earlier in 2023 and deal with any loose ends that would otherwise become impossible to tie up after that date.
This abrupt termination...
Thanks!
I agree. This is unfortunately often done in various fields of research where familiar terms are reused as technical terms.
For example, in ordinary language "organic" means "of biological origin", while in chemistry "organic" describes a type of carbon compound. Those two definitions mostly coincide on Earth (most such compounds are of biological origin), but when astronomers announce they have found "organic" material on an asteroid this leads to confusion.
