This post is a not a so secret analogy for the AI Alignment problem. Via a fictional dialog, Eliezer explores and counters common questions to the Rocket Alignment Problem as approached by the Mathematics of Intentional Rocketry Institute.
MIRI researchers will tell you they're worried that "right now, nobody can tell you how to point your rocket’s nose such that it goes to the moon, nor indeed any prespecified celestial destination."

Popular Comments
Recent Discussion
when i was younger, pre-rationalist, i tried to go on hunger strike to push my abusive parent to stop funding this.
they agreed to watch this as part of a negotiation. they watched part of it.
they changed their behavior slightly -- as a negotiation -- for about a month.
they didn't care.
they looked horror in the eye. they didn't flinch. they saw themself in it.
Authors: Senthooran Rajamanoharan*, Arthur Conmy*, Lewis Smith, Tom Lieberum, Vikrant Varma, János Kramár, Rohin Shah, Neel Nanda
A new paper from the Google DeepMind mech interp team: Improving Dictionary Learning with Gated Sparse Autoencoders!
Gated SAEs are a new Sparse Autoencoder architecture that seems to be a significant Pareto-improvement over normal SAEs, verified on models up to Gemma 7B. They are now our team's preferred way to train sparse autoencoders, and we'd love to see them adopted by the community! (Or to be convinced that it would be a bad idea for them to be adopted by the community!)

They achieve similar reconstruction with about half as many firing features, and while being either comparably or more interpretable (confidence interval for the increase is 0%-13%).
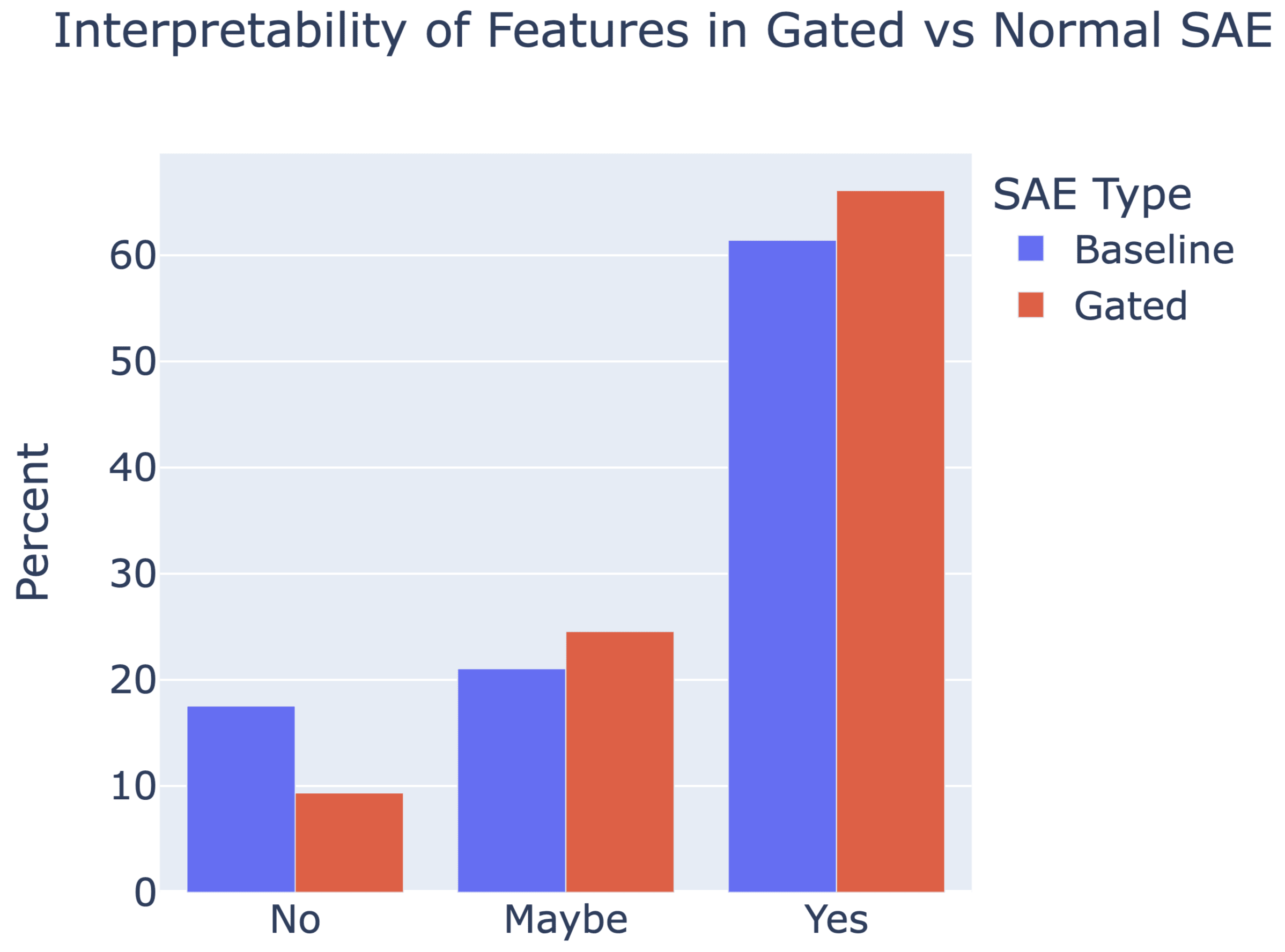
See Sen's Twitter summary, my Twitter summary, and the paper!
Hi any idea how this would compare to just replacing the loss with a smoothed loss function? Something like (summed across the sparse representation).
People in rich countries are happier than people in poor countries generally (this is both people who say they are "happy" or "very happy", and self-reported life satisfaction), see many of the graphs here https://ourworldindata.org/happiness-and-life-satisfaction
In general it seems like richer countries also have lower suicide rates: "for every 1000 US dollar increase in the GDP per capita, suicide rates are reduced by 2%"
Warning: This post might be depressing to read for everyone except trans women. Gender identity and suicide is discussed. This is all highly speculative. I know near-zero about biology, chemistry, or physiology. I do not recommend anyone take hormones to try to increase their intelligence; mood & identity are more important.
Why are trans women so intellectually successful? They seem to be overrepresented 5-100x in eg cybersecurity twitter, mathy AI alignment, non-scam crypto twitter, math PhD programs, etc.
To explain this, let's first ask: Why aren't males way smarter than females on average? Males have ~13% higher cortical neuron density and 11% heavier brains (implying more area?). One might expect males to have mean IQ far above females then, but instead the means and medians are similar:
My theory...
It implicitly does compare trans women to other women in talking about the performance similarity between men and women:
"Why aren't males way smarter than females on average? Males have ~13% higher cortical neuron density and 11% heavier brains (implying 1.112/3−1=7% more area?). One might expect males to have mean IQ far above females then, but instead the means and medians are similar"
So OP is saying "look, women and men are the same, but trans women are exceptional."
I'm saying that identifying the exceptionality of trans women ignores the environmental...
Crosspost from my blog.
If you spend a lot of time in the blogosphere, you’ll find a great deal of people expressing contrarian views. If you hang out in the circles that I do, you’ll probably have heard of Yudkowsky say that dieting doesn’t really work, Guzey say that sleep is overrated, Hanson argue that medicine doesn’t improve health, various people argue for the lab leak, others argue for hereditarianism, Caplan argue that mental illness is mostly just aberrant preferences and education doesn’t work, and various other people expressing contrarian views. Often, very smart people—like Robin Hanson—will write long posts defending these views, other people will have criticisms, and it will all be such a tangled mess that you don’t really know what to think about them.
For...
Hmm, this sounds like an awfully contrarian take to me.
People have been posting great essays so that they're "fed through the standard LessWrong algorithm." This essay is in the public domain in the UK but not the US.
From a very early age, perhaps the age of five or six, I knew that when I grew up I should be a writer. Between the ages of about seventeen and twenty-four I tried to abandon this idea, but I did so with the consciousness that I was outraging my true nature and that sooner or later I should have to settle down and write books.
I was the middle child of three, but there was a gap of five years on either side, and I barely saw my father before I was eight. For this and other reasons I...
If math education was better at the time (or today, for that matter) he probably would have had an even more general skillset and thought process.
Probably not nearly to the degree of Von Neumann, of course, but I still like to think about what he would have achieved. There were probably many things that were instrumentally convergent (e.g. a formalized concept of instrumental convergence that's universal for all mind configurations, instead of just all human cultures which he explored substantially).
About a year ago I decided to try using one of those apps where you tie your goals to some kind of financial penalty. The specific one I tried is Forfeit, which I liked the look of because it’s relatively simple, you set single tasks which you have to verify you have completed with a photo.
I’m generally pretty sceptical of productivity systems, tools for thought, mindset shifts, life hacks and so on. But this one I have found to be really shockingly effective, it has been about the biggest positive change to my life that I can remember. I feel like the category of things which benefit from careful planning and execution over time has completely opened up to me, whereas previously things like this would be largely down to the...
My depression is currently well-controlled at the moment, and I actually have found various methods to help me get things done, since I don't respond well to the simplest versions of carrot-and-stick methods. The most pleasant is finding someone else to do it with me (or at least act involved while I do the actual work).
On the other hand, there have been times when procrastinating actually gives me a thrill, like I'm getting away with something. Mediocre video games become much more appealing when I have work to avoid.
U.S. Secretary of Commerce Gina Raimondo announced today additional members of the executive leadership team of the U.S. AI Safety Institute (AISI), which is housed at the National Institute of Standards and Technology (NIST). Raimondo named Paul Christiano as Head of AI Safety, Adam Russell as Chief Vision Officer, Mara Campbell as Acting Chief Operating Officer and Chief of Staff, Rob Reich as Senior Advisor, and Mark Latonero as Head of International Engagement. They will join AISI Director Elizabeth Kelly and Chief Technology Officer Elham Tabassi, who were announced in February. The AISI was established within NIST at the direction of President Biden, including to support the responsibilities assigned to the Department of Commerce under the President’s landmark Executive Order.
...Paul Christiano, Head of AI Safety, will design
I agree there other problems the EA biosecurity community focuses on, but surely lab escapes are one of those problems, and part of the reason we need biosecurity measures? In any case, this disagreement seems beside the main point that I took Adam to be making, namely that the track record for defining appropriate units of risk for poorly understood, high attack surface domains is quite bad (as with BSL). This still seems true to me.
The history of science has tons of examples of the same thing being discovered multiple time independently; wikipedia has a whole list of examples here. If your goal in studying the history of science is to extract the predictable/overdetermined component of humanity's trajectory, then it makes sense to focus on such examples.
But if your goal is to achieve high counterfactual impact in your own research, then you should probably draw inspiration from the opposite: "singular" discoveries, i.e. discoveries which nobody else was anywhere close to figuring out. After all, if someone else would have figured it out shortly after anyways, then the discovery probably wasn't very counterfactually impactful.
Alas, nobody seems to have made a list of highly counterfactual scientific discoveries, to complement wikipedia's list of multiple discoveries.
To...
The RLCT = first-order term for in-distribution generalization error
Clarification: The 'derivation' for how the RLCT predicts generalization error IIRC goes through the same flavour of argument as the one the derivation of the vanilla Bayesian Information Criterion uses. I don't like this derivation very much. See e.g. this one on Wikipedia.
So what it's actually showing is just that:
- If you've got a class of different hypotheses , containing many individual hypotheses .
- And you've got a prior ahead of time that s
