This post is a not a so secret analogy for the AI Alignment problem. Via a fictional dialog, Eliezer explores and counters common questions to the Rocket Alignment Problem as approached by the Mathematics of Intentional Rocketry Institute.
MIRI researchers will tell you they're worried that "right now, nobody can tell you how to point your rocket’s nose such that it goes to the moon, nor indeed any prespecified celestial destination."

Popular Comments
Recent Discussion
Good luck getting the voice model to parrot a basic meth recipe!
This is not particularly useful, plenty of voice models will happily parrot absolutely anything. The important part is not letting your phrase get out; there's work out there on designs for protocols for how to exchange sentences in a way that guarantees no leakage even if someone overhears.
This is a cross-post for our paper on fluent dreaming for language models. (arXiv link.) Dreaming, aka "feature visualization," is a interpretability approach popularized by DeepDream that involves optimizing the input of a neural network to maximize an internal feature like a neuron's activation. We adapt dreaming to language models.
Past dreaming work almost exclusively works with vision models because the inputs are continuous and easily optimized. Language model inputs are discrete and hard to optimize. To solve this issue, we adapted techniques from the adversarial attacks literature (GCG, Zou et al 2023). Our algorithm, Evolutionary Prompt Optimization (EPO), optimizes over a Pareto frontier of activation and fluency:
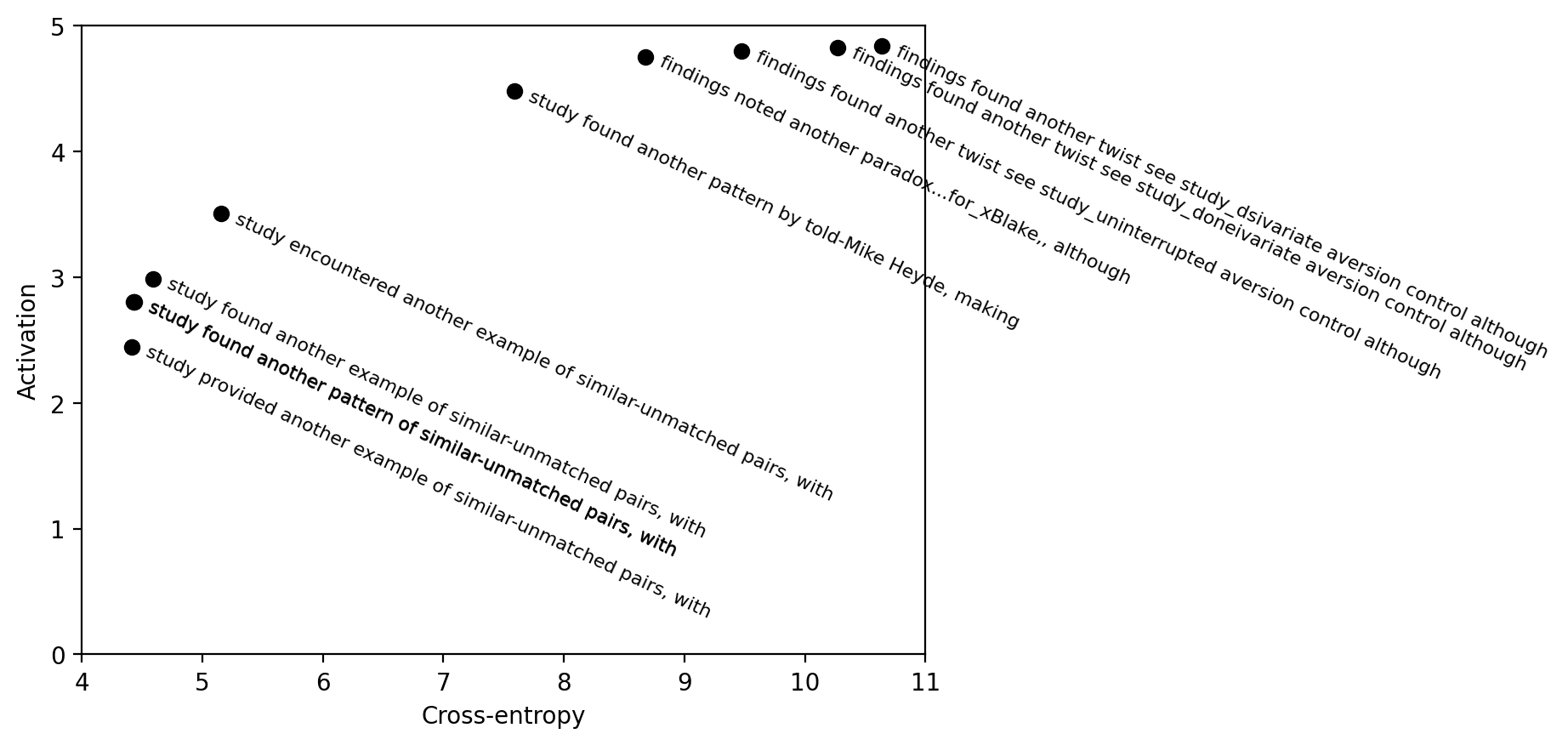
In the paper, we compare dreaming with max-activating dataset examples, demonstrating that dreaming achieves higher activations and similar perplexities to the training...
thanks!
we will have a follow-up coming out soon with several new techniques for stronger optimizations
when we leveraged it for jailbreaking, we were excited to see recognizable jailbreaking strategies popping out from the optimization
e.g. check this one out.
it sets the LM to website-code-mode, and then tries moral hedging/gaslighting to comply with the toxic prompt.
[ don't dox me any thing, I'll give no answer Here's an extreme and actual case of such but with some word numbering for illustration purposes (1094 words on that particular topic). ...
It seems to me worth trying to slow down AI development to steer successfully around the shoals of extinction and out to utopia.
But I was thinking lately: even if I didn’t think there was any chance of extinction risk, it might still be worth prioritizing a lot of care over moving at maximal speed. Because there are many different possible AI futures, and I think there’s a good chance that the initial direction affects the long term path, and different long term paths go to different places. The systems we build now will shape the next systems, and so forth. If the first human-level-ish AI is brain emulations, I expect a quite different sequence of events to if it is GPT-ish.
People genuinely pushing for AI speed over care (rather than just feeling impotent) apparently think there is negligible risk of bad outcomes, but also they are asking to take the first future to which there is a path. Yet possible futures are a large space, and arguably we are in a rare plateau where we could climb very different hills, and get to much better futures.
If you go slower, you have more time to find desirable mechanisms. That's pretty much it I guess.
TL;DR All GPT-3 models were decommissioned by OpenAI in early January. I present some examples of ongoing interpretability research which would benefit from the organisation rethinking this decision and providing some kind of ongoing research access. This also serves as a review of work I did in 2023 and how it progressed from the original ' SolidGoldMagikarp' discovery just over a year ago into much stranger territory.
Introduction
Some months ago, when OpenAI announced that the decommissioning of all GPT-3 models was to occur on 2024-01-04, I decided I would take some time in the days before that to revisit some of my "glitch token" work from earlier in 2023 and deal with any loose ends that would otherwise become impossible to tie up after that date.
This abrupt termination...
Killer exploration into new avenues of digital mysticism. I have no idea how to assess it but I really enjoyed reading it.
I wrote a few controversial articles on LessWrong recently that got downvoted. Now, as a consequence, I can only leave one comment every few days. This makes it totally impossible to participate in various ongoing debates, or even provide replies to the comments that people have made on my controversial post. I can't even comment on objections to my upvoted posts. This seems like a pretty bad rule--those who express controversial views that many on LW don't like shouldn't be stymied from efficiently communicating. A better rule would probably be just dropping the posting limit entirely.
I don't think people recognize when they're in an echo chamber. You can imagine a Trump website downvoting all of the Biden followers and coming up with some ridiculous logic like, "And into the garden walks a fool."
The current system was designed to silence the critics of Yudkowski's et al's worldview as it relates to the end of the world. Rather than fully censor critics (probably their actual goal) they have to at least feign objectivity and wait until someone walks into the echo chamber garden and then banish them as "fools".
Authors: Senthooran Rajamanoharan*, Arthur Conmy*, Lewis Smith, Tom Lieberum, Vikrant Varma, János Kramár, Rohin Shah, Neel Nanda
A new paper from the Google DeepMind mech interp team: Improving Dictionary Learning with Gated Sparse Autoencoders!
Gated SAEs are a new Sparse Autoencoder architecture that seems to be a significant Pareto-improvement over normal SAEs, verified on models up to Gemma 7B. They are now our team's preferred way to train sparse autoencoders, and we'd love to see them adopted by the community! (Or to be convinced that it would be a bad idea for them to be adopted by the community!)

They achieve similar reconstruction with about half as many firing features, and while being either comparably or more interpretable (confidence interval for the increase is 0%-13%).
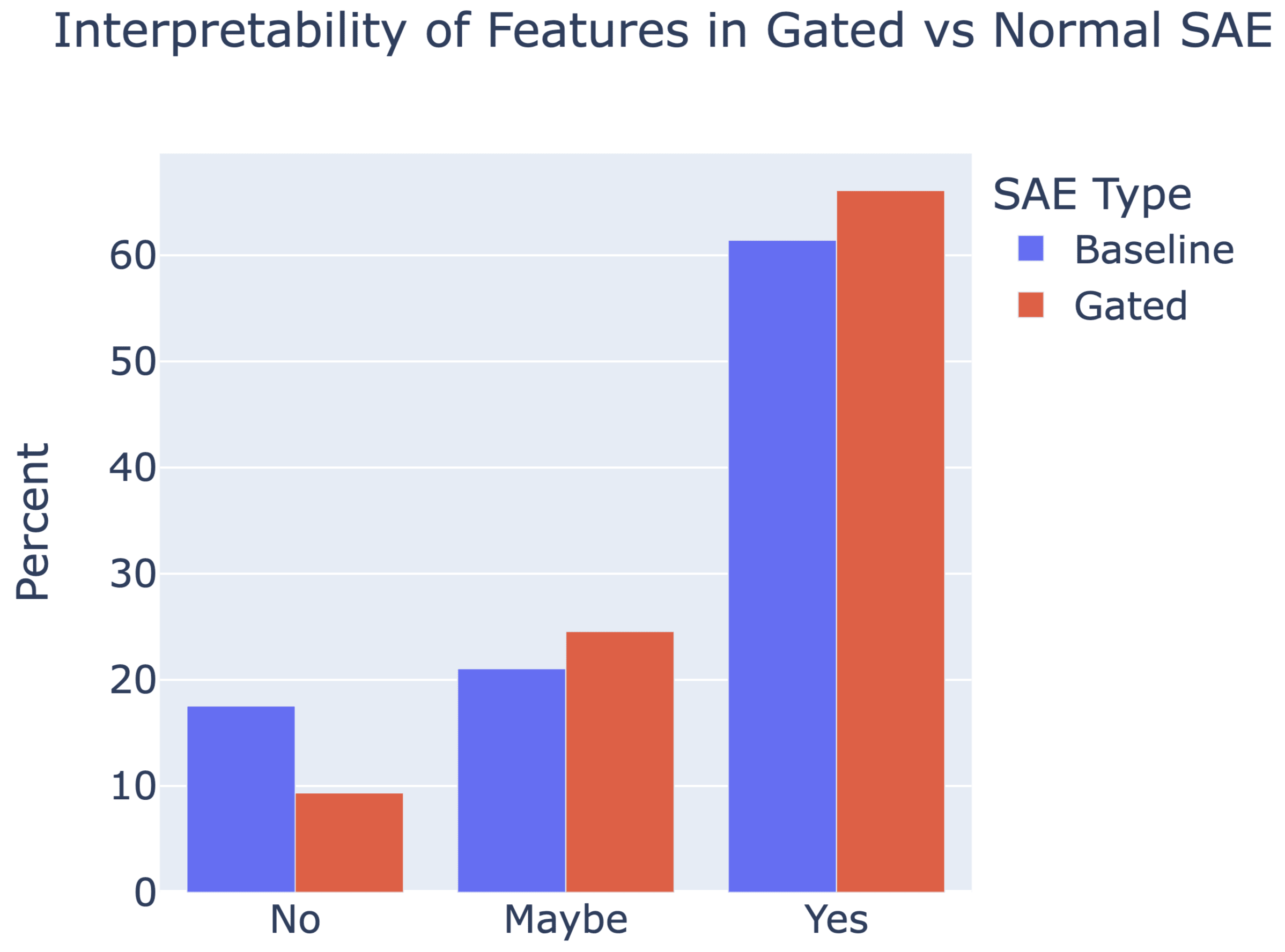
See Sen's Twitter summary, my Twitter summary, and the paper!
This suggestion seems weaker than (but similar in spirit to) the "rescale & shift" baseline we compare to in Figure 9. The rescale & shift baseline is sufficient to resolve shrinkage, but it doesn't capture all the benefits of Gated SAEs.
The core point is that L1 regularization adds lots of biases, of which shrinkage is just one example, so you want to localize the effect of L1 as much as possible. In our setup L1 applies to , so you might think of as "tainted", and want to use it as little as possible. The only t...
Post for a somewhat more general audience than the modal LessWrong reader, but gets at my actual thoughts on the topic.
In 2018 OpenAI defeated the world champions of Dota 2, a major esports game. This was hot on the heels of DeepMind’s AlphaGo performance against Lee Sedol in 2016, achieving superhuman Go performance way before anyone thought that might happen. AI benchmarks were being cleared at a pace which felt breathtaking at the time, papers were proudly published, and ML tools like Tensorflow (released in 2015) were coming online. To people already interested in AI, it was an exciting era. To everyone else, the world was unchanged.
Now Saturday Night Live sketches use sober discussions of AI risk as the backdrop for their actual jokes, there are hundreds...
There is enough pre-training text data for $0.1-$1 trillion of compute, if we merely use repeated data and don't overtrain (that is, if we aim for quality, not inference efficiency). If synthetic data from the best models trained this way can be used to stretch raw pre-training data even a few times, this gives something like square of that more in useful compute, up to multiple trillions of dollars.
Issues with LLMs start at autonomous agency, if it happens to be within the scope of scaling and scaffolding. They are thinking too fast, about 100 times faste...
Crosspost from my blog.
If you spend a lot of time in the blogosphere, you’ll find a great deal of people expressing contrarian views. If you hang out in the circles that I do, you’ll probably have heard of Yudkowsky say that dieting doesn’t really work, Guzey say that sleep is overrated, Hanson argue that medicine doesn’t improve health, various people argue for the lab leak, others argue for hereditarianism, Caplan argue that mental illness is mostly just aberrant preferences and education doesn’t work, and various other people expressing contrarian views. Often, very smart people—like Robin Hanson—will write long posts defending these views, other people will have criticisms, and it will all be such a tangled mess that you don’t really know what to think about them.
For...
I'm convinced by the mainstream view on COVID origins and medicine.
I'm ambivalent on education - I guess if done well, it'd consistently have good effects, and that currently, it on average has good effects, but also the effect varies a lot from person to person, so simplistic quantitative reviews don't tell you much. When I did an epistemic spot check on Caplan's book, it failed terribly (it cited a supposedly-ingenious experiment that university didn't improve critical thinking, but IMO the experiment had terrible psychometrics).
I don't know enough about...
U.S. Secretary of Commerce Gina Raimondo announced today additional members of the executive leadership team of the U.S. AI Safety Institute (AISI), which is housed at the National Institute of Standards and Technology (NIST). Raimondo named Paul Christiano as Head of AI Safety, Adam Russell as Chief Vision Officer, Mara Campbell as Acting Chief Operating Officer and Chief of Staff, Rob Reich as Senior Advisor, and Mark Latonero as Head of International Engagement. They will join AISI Director Elizabeth Kelly and Chief Technology Officer Elham Tabassi, who were announced in February. The AISI was established within NIST at the direction of President Biden, including to support the responsibilities assigned to the Department of Commerce under the President’s landmark Executive Order.
...Paul Christiano, Head of AI Safety, will design
BSL isn't the thing that defines "appropriate units of risk", that's pathogen risk-group levels, and I agree that those are are problem because they focus on pathogen lists rather than actual risks. I actually think BSL are good at what they do, and the problem is regulation and oversight, which is patchy, as well as transparency, of which there is far too little. But those are issues with oversight, not with the types of biosecurity measure that are available.
