You can question a tradition without getting rid of it.
To be more concrete, what I have in mind are things like religious traditions (e.g. "light a candle in the church") or superstitions (e.g. "don't sing at the table because you'll marry a gypsy") or even culinary traditions that differ between cultures. Occasionally people in my family have been trying to defend such things after I explicitly question them and despite evidence disproving them.
Mr Kokotajlo, one of the authors of this AI 2040 scenario, describes it as follows:
If you read the scenario, you'll see that the regulations are mostly about what people can do with giant compute clusters, and not about the ideas themselves. The ideas themselves are required to be totally transparent to the public.
Although regulations on giant compute clusters would give humanity more time, they might not avert extinction by themselves. If allowed to communicate freely as they have been, the research community might discover and publish a machine-learn...
Nearly everyone in Silicon Valley is a transhumanist. Transhumanism is the water they swim in, the air they breathe. It’s so ubiquitous that many don’t even call themselves transhumanists, for the same reason that I’ve never publicly stated that I’m a round-Earther — of course I’m a round-Earther. What else would I be?
This must be super false right? I would have guessed that like 5-10% of adults in Silicon Valley are transhumanists, in the sense that they believe that "Transhumanism is the idea that we should develop advanced technologies to radically reen...
I though the answer was "assume you're simulated and follow FDT to save real-you the trouble of ever getting into this situation in real life". Out of the all arguments to take the bomb this is the only one I've ever heard which I can at least understand where it's coming from.
If that is not the FDT response then, I guess I don't know why you'd ever really blow yourself up. I did read the whole post, including rereading the example against just now.
But what I got from it was mostly the insight that FDT kind of answers a different question than CDT, in that it's goal is to shape what situations you end up in, not necessarily how to get the best result out of a given situation.
Generally, understanding cause and effect of dismantling tradition is hard. That's what the Cassava root example demonstrates.
It doesn't follow from the text, it's just based on my anecdotal experience.
It's not clear to me how anecdotal experience would form a basis for that. Anecdotal experience can tell you that you are valuing tradition less then the average person, but not really whether most of your experiences of getting rid of tradition have complex unforeseen negative experiences that are more like getting rid of Cassava root prep.
I have broad agreement with this overall document, with some relatively minor/subjective disagreements on what would be the optimal point to pause further capabilities work [1] , but unless A) I have missed the section where you address this directly, or B) you have deliberately omitted this for strategic reasons, there does seem to be a serious oversight in the current plan that could render it unviable unless a solution to it is found:
You correctly point out that it is in the interests of China to agree to this treaty, but have not explained wh...
FDT only applies to embedded agents
I mean, unembedded agents are not necessarily unpredictable? You don't need to fully instantiate an agent to predict it, e.g. 100 parameter N-grams model can predict human choice in Rock Paper Scissions, after observing some number of moves. So, even if agent and the universe are separate and converse through a narrow channel, you need to track logical/correlational dependencies of your choice with stuff in universe.
...Functional Decision Theory (FDT) is a decision theory for a rational agent X who holds the rational be
My intuition was that if you are on the more insecure end of the spectrum, it can make you feel less intelligent.
Total research transparency feels a bit too galaxy-brained for me. It makes non-robust assumptions that newly discovered techniques won't be usable to enhance already existing open-weights models to dangerous capability levels. I also think the disincentive for research is overstated as it neglects first-mover advantage.
A counterexample is a variant of the typical mind fallacy: if you perfectly understand something, it feels so obvious that you tend to forget what was not obvious before. So professors are regularly worse at explaining a difficult concept than teaching assistants: because the latter still know what makes it hard to understand.
It’s perfectly reasonable for TESCREALists to not want to be called “TESCREALists” — though it doesn’t change the fact that they are
You can, in fact, say that about literally any slur.
'Already, Sol has been transforming our research program. As one example, GPT-5.6-Sol autonomously post-trained GPT-5.6-Luna.' https://youtu.be/Wq45rvPGNHs?t=1240
We have a get involved page for verification in particular. It tracks the current state of play wrt verification and what still needs to be done: https://ai-2040.com/supplements/verification-plan/get-involved

We might do a blog post on other actions as well.
Very interesting post! Is there a plan to open-source this? This can be a very useful starting point for further research.
I am particularly interested in the results with bolding since they seem clean & counterintuitive. My quick replication with Claude suggests that de-bolding the right data (but not just the coding data as you did) does help. Claude also cannot replicate the initial 29-96 gap (base comes out 69% for me with chat template), potentially due to the question distribution being different. These replications could be off in subtle ways so ...
I'm at 2029 or 2028 median now, not sure. We'll try to do a reassessment of timelines soon and get out an update.
They see “TESCREAL” as a term of abuse — perhaps even a slur. This isn’t entirely inaccurate, as Gebru and I introduced the term to describe people we see as deeply problematic (racist, sexist, etc.) and dangerous. Indeed, we argue that the TESCREAL movement is just the most recent iteration of what’s been called the “eternal return of eugenics.”
That is, by your own admission it's totally accurate, not merely "not entirely inaccurate". You say right there that you introduced the term for exactly that purpose: to be an accusation of racism, sexism, eugen...
We want a non-transferable currency of accuracy.
is this possible? i could make a market on "account XYZ will get funded to $ amount on such and such day", and bet against it. the market will find some price for marking reputation in dollars.
You might like this video on the cosmic distance ladder between Terry Tao and 3Blue1Brown. The starting point is pretty similar to what you said, but they kept going!
<notice>Curated! This post contains both (1) superbly readable and accessible explanation that makes me feel like I understand something I thought I already did to a yet deeper degree, (2) elegant novel experiment to highlight their points. I have definitely updated on the significance of roles from this post.
Role tags were a formatting trick that became the security architecture and the cognitive scaffolding of modern LLMs.
I'd also say the point of the steady evolution of roles and how they're used (and leave open vulnerability) feels like it says ...
Model Transparency Team at UK AISI tested GPT 5.6 Sol pre-deployment. More details in thread / system card. We're hoping to share more details on our most interesting results soon.
https://en.wikipedia.org/wiki/Buyers_club, and the far less legible "get a group together to buy wholesale" ideas are not new or uncommon. Artificial monopsony (all/most consumers acting as one) is pretty rare, but much like the other direction, doesn't require perfection to be worthwhile.
It would be nice to link a supplement with some actions that people with different levels of resources can take to make progress on this. I’m sure this is coming, hopefully soon for momentum purposes.
I wonder how the AIFutures' team's timelines have changed (esp after Fable, Sol etc)
Thanks for the post - it gave me plenty of food for thought!
On the object level: IMHO, asking the question "OK, but if you are in the situation, what do you do?" follows from an implicit rejection of the scenario's embeddedness — and without embeddedness, FDT doesn't make sense. I've written a 3-min post elaborating on this.
I know you and the AI futures team have likely queued up an update on AI timelines that will come out pretty soon, so I don't want to disrupt that project, but after the AI timelines update comes up, I'd like you to start modelling data trends of AIs (as well as how AIs could maybe need less data than currently) as well as how you modeled compute trends, because I find it reasonably plausible by 2028-2030, the bottleneck to further AI progress will start becoming data, rather than compute.
In particular, I expect high-quality data to become both much more v...
Some have embraced the acronym in the manner of a reclaimed pejorative, the "LGBTESCREAL" Twitter cluster most clearly. I think Marc Andreessen tried to do a similar thing and gave up.
Thanks!
Sorry if you already said this, but are you assuming that everything the AI outputs is reliably checkable by humans? If yes, I’m skeptical about the “strategic constraints” of §6.1. Or if no, I don’t understand how risk-aversion helps.
Let’s say Company A has its brand new risk-averse ASI in a box. The problem to be solved is: maybe some Company B somewhere on Earth will make a long-term-optimizing ruthless out-of-control ASI that then eats the world, in the near future. And my question is: How is Company A (or anyone else) supposed to solve this pro...
In fact, we should do this ASAP, before we end up in such a situation. So let’s do it right now, together, on three: one... two... three!
I would have liked a warning before this phrase, because as I was reading it, one part of my brain automatically started thinking about trying to precommit to the Great Commitment, while another was (literally) screaming very loudly that it would be extremely stupid to do so without thinking it through. I was just left confused for a bit.
Of course, this kind of precommitment, if it is possible at all, would not arise simp...
I would prefer way less bolding, though it was said: de gustibus non disputandum.
I gave up and went on tirzepatide, which mostly works. Down about 30 lbs. in two years and now on the highest dose. It does nothing for metabolism for me, actually clawing some back that I'd normally have in a falling phase. Discovering the antihistamines I take daily are correlated with 20 lbs. of gain in men was a big one, and I cut that dose back to 1/4. https://doi.org/10.1038/oby.2010.176
Created a Kalman model that filtered out day-to-day fluctuations to reconstitute true daily body composition, but tuning that model is a tradeoff. Adjusting to minimi...
It's a sign that I failed at life, that despite having 30 years to lay the groundwork, there's no one at the party talking about how the survival of consciousness depends on those being quantum "uploads" rather than just digital ones...
Also, I am very skeptical of scenarios according to which singularity on Earth is followed by maximum conquest of the future lightcone, but I don't have a clearly favored alternative model of the future.
There are tons of startups now that are trying to work on this problem and sell the results to the labs. Most are building bespoke individual environments on a contract basis, but I would hope and assume that they are trying to work on how to do this at scale, e.g. build evaluation systems that can look for reward hacking and correctness issues.
Some reporting here: https://techcrunch.com/2025/09/21/silicon-valley-bets-big-on-environments-to-train-ai-agents/
“I wish it need not have happened in my time,” said Frodo. “So do I,” said Gandalf, “and so do all who live to see such times.”
u make some good points but i think you hold it to an unreasonably high standard - adversaries not gaining anything from knowing the defense is a very common setting in cryptography and such but in backdoor defense, it essentially doesn't exist. in fact, the reason why I'm excited about these results anyway is not because I think an intelligent person can't design something to circumvent it - they definitely can! - but because it indicates robustness against prolonged SGD and the resulting failure modes like reward hacking etc: if even a gradient, literall...
But we do believe that all TESCREALists share more or less the exact same vision of the future: a posthuman paradise among the stars through the creation of ASI.
So why not call them posthumanists? That is at least a thing some of the relevant people call themselves or are credibly described as. Posthumanist is also an actual word. It further communicates what your specific criticism is, nobody knows what a TESCREAL is unless you explain it, whereas the meaning of posthumanist is inferable from the structure of the word itself. Sure most of the relevant people will object to being called posthumanists, but they will also object to being called TESCREAL so.
GRAM approximates data filtering and the question is just as applicable there: Is data filtering useful when models can re-derive, continually learn, or in-context learn?
I would argue yes, data filtering (and therefore GRAM) are still useful in this setting. Lets just stick to in-context learning case, e.g. you feed an advanced LLM huge amounts of knowledge on virology and it can derive instructions for building bioweapons in-context. For closed models, the developer could still monitor the in-context information and flag it before the model provides ...
Did you test Shampoo or SOAP?
I think that if you define alignment this way, saying that there can be aligned AIs that kill people should be met with "of course they can, because that is true of just about every machine with any physical capability at all". If a car counts as an aligned system that kills people, then aligned systems that kill people are acceptable.
I agree with Korzybski that our problems are representational. As extremely cognitively limited beings much of our progress stems from which sorts of problems we can easily represent and communicate about, such that a variety of humans can become interested and work on them. My unusual claim in this area is that we had an aborted attempt to transcend the modernist representations when they proved insufficient in the face of problems in foundational math, physics, philosophy of science, and politics (impossibility results in attempts at preference aggregati...
The text of the very post you cite is arguing against that stance.
What? I specifically stated that Eliezer didn't buy into it, which is what you are quoting.
"And the world soon - so very, very soon - would no longer be the same world.", well, canon ending is that the destroyer of worlds, extinguisher of stars is what we are left with. This just speed runs his coming?
Good read, though!
Plan A for anyone looking for a direct link. Awesome to finally see this out from the AIFP team!
Some theorize that working memory is really an attention thing, in that it has to be actively reinforced with other noise or stuff suppressed in order to function.
This is where the whole "ADHD leads to lower working memory" seems to come from, even though usually when a layman says that they seem to not be thinking about, say, how many sequential digits I can keep in my head (which made me quite confused - they name-drop working memory but then talk about organization, sustaining focus, etc., never even mentioning how they are supposed to be related, and giving me confused looks when I ask!).
This is a neat idea, though I'm not sure how practical this defense is, as by default it seems to be high recall but low precision (I would expect there to be a lot ways beyond backdoor triggers to see really high
Also, in the defense-aware adversary table you provide,
With my original comment, I am saying that doing something once is not always extremely helpful for doing it later times. I am not sure whether Covid helped learning/preparing for a next pandemic, but I think it had some negative effects for that with respect to the attitudes of the population, and positive effects with respect to scientific insights. I am much less sure whether it applies to an AI pause!
I am skeptical whether the word "trial run" is a good word for a real-world AI pause or pandemic measures starting in 2020. A trial run is a preliminary t...
AIs will be evaluated, inspected, and selected by us, and their behavior will be determined directly by our engineering.
I think the "us" here is meaningfully and importantly different from the "us" in the rest of this paragraph. This "us" may include the majority of people reading this article, but it doesn't include me or vast the majority of humans, and that has a meaningful impact on how comforting this prediction is able to be.
Great post!
Another argument in favour of this is that RL is not very information dense, and will probably stay that way for quite a while. Constitutional training / SDF probably conveys quite a lot of information, and so even if RL is scaled up these efforts will probably be scaled up too, and still contribute most of the bits used to pinpoint the model's parameters after pre-training. Also one way RL will be scaled up is longer horizon tasks, which will provide roughly similar total information to short horizon ones (at least for RLVR / outcome-based RL),...
Does glossing over large inferential distances correlate with poor understanding? I’d expect no. A teacher who is leaving big chunks of an argument as exercises for the reader is a poor communicator, but their failure is in modeling the listener and not necessarily understanding the subject. They may talk like that about everything.
Your point is more broad and you acknowledged it’s not always true, but this specific failure mode doesn’t seem correlated with understanding. You can understand something very well but will fail at walking someone to your conclusion if you make false assumptions about your audience’s knowledge or processing speed. See bad physics professors as an example of this.
It doesn't follow from the text, it's just based on my anecdotal experience. I could very well be wrong.
For the no sex before marriage, I'm not convinced the effects you describe are downstream of dismantling that tradition. For divorse, why not downstream of more independence and decreased stigma? For low childbirth, why not downstream of contraception and changed economic conditions? I also disagree that low childbirth rate is a problem, but that's a separate question.
Anyway, I get your general point.
This isn't an AI Box game.
It's either:
1) A debate about whether there's any text eval that can make an AI worth "letting out" (whatever that means; open sourcing the weights? give API access?) If the Keeper changes their mind they need to report it.
2) A game with the mechanics: default-winner can chose to lose, default-winner has to read what the AI writes for at least 2 hours. Then the default-loser has to convince the default-winner to lose. There are various interesting strategies, but they have very little to do with AIs in a box. I might share some l...
Yep, that all sounds right to me! If you can only access looks-good-high-effort, tie training can't take you beyond that, but it will shrink the weight on looks-good-low-effort (along with any other spurious features that happen to differ across your pairs).
This is a better-argued version of something I feel like I've been circling for a while, thanks for writing it.
Something you didn't suggest but I think might be a pitfall to avoid: I don't think you can hill-climb on articulacy by getting (for example) Fable to explain things to Haiku. The ways in which a weak model misunderstands are (I claim) sufficiently different from the ways in which a low-context human misunderstands, that I don't think weak LLMs are a good proxy for low-context humans
I think most people don't question traditions sufficiently
I'm not sure how this follows from your text, especially given the Cassava root example.
In most cultures, the traditional treatment of acute respiratory tract infections is done via given chicken bone broth. The studies we have suggest that this is more effective than what mainstream medicine has to offer for most acute respiratory tract infections (even when of course it's not studied well enough to draw definite conclusions).
Even in the West there's still the cultural memory for that so the relev...
- Much of Damon Binder's work is based on a methodology of speculative engineering, i.e. thinking about the feasibility of various ways to solve a problem. See:
- How much this kind of work update [smart, reasonable] people on the questions he discusses?
- How reliable is this methodology? I'm not sure.
- It seems IMO easy for th
Does GRAM remain useful when models become capable of learning continually and re-deriving any missing knowledge?
Qwen 3.6 has preserve_thinking option which I guess preserves thinking between turns. But I haven't used that.
Fair enough, I haven't seen that link before, interesting stuff. You've inspired me to try an extra high protein diet and see how I feel. Interestingly the USDA's new guideline is 1.2g-1.6g/kg and that's not even for strength training.
I think the only thing I'd change with the framing is that I got the impression 1.6g-2.2g/kg was required for strength training rather than what you need to maximize gains. Otherwise I retract my critic of the science, the evidence does seem to point towards 2g/kg or perhaps more as being optimal.
Log-scoring really means you're just multiplying together the probabilities you assigned to every thing that did turn out true.
If every time you say an event has probability p, and it happens, you assign yourself log p points, you might as well just take all the p's you're taking logs of and multiply them together first, and then take the log after.
The logarithm is what creates addition (which is how you accumulate points in any points-based system) from multiplication (the thing probabilities want to do with each other).
I guess the reason to take the actu...
I wonder WHICH proof you were taught. Wikipedia has two proofs, of which the second one seems to be more intuitive. It works by repeatedly splitting the interval into subintervals, then noticing that a subinterval has infinitely many points and using this fact. Receiving "an internal appearance of the validity of the arguments" is NOT how math is supposed to work, it is supposed to rely on rigorous proofs.
I've increasingly tended to agree that it's not great that the AI futures model (and so many other models) doesn't have any modeling of data requirements, but in their (partial) defense, I can see 2 plausible reasons:
- For the last couple of decades, compute was the bottleneck, and we are still in a compute-bottlenecked regime, but absent breakthroughs soon, we will be bottlenecked on data by 2028 for high quality tasks (and high quality tasks are increasingly more valuable.)
- I suspect the AI futures team assumes that post-automated coder, sample efficiency o
Re: Problem 2
My pillow has some adjustable height thin cushions. I feel like something similar must be purchasable separately, "pillow booster" might be the right term but I'm not sure.
https://www.amazon.com/LOFE-Adjustable-Memory-Pillows-Layer/dp/B0C2TF6Q1M?th=1
This isn't quite the threat model I normally think about when discussing these kinds of problems. I imagine that we have two variables: looks-good-low-effort and is-good, which are correlated at some pretty high level on a non-pathological dataset, say 0.8. The dataset is then labelled according to looks-good-low-effort. The AI learns to put ~all its weight on learns-good-low-effort because that's the best possible predictor.
What you want is some set of data which ties on is-good but varies on looks-good-low-effort. Unfortunately, you don't have access to ...
The thing that negatively correlates is the subcomponents of whatever you're actually filtering for. If conversational wittiness is not much selected for in, say, being a stem major with high grades, then it won't negatively correlate with intelligence even among that group.
Was this in CC or through the chat interface? It’s plausible the discarding behaviour is different between the two
One Q I have:
How would this change if we augmented the Transformer so the first layer can "look back" at the final layer from the previous token?
Optimist: Now the first layer activations can express very complicated concepts that involve many steps of sequential sequencing. So perhaps this helps a lot.
Sceptical: but from the perspective of the weights that produce the first layer activations, all the new concepts still look like gobbledegook.
Optimist: True, but in this set-up the the weights are describing the learning rule, they're not trying to "underst...
iirc i asked some opus to write a story in a thinking block and then count to 100 while ruminating on the story, then on the next turn i asked it for a description of the story, then i regenerated the last turn, then both turns, then the last turn, and the first two descriptions were similar and the last two were similar.
OpenClaw itself didn’t, but the agentic systems have. Last year, I thought I’d have a robot assistant by now, and I’d be a software engineering company on my own by next year. Now, I regularly have a team of robots write my code.
I’m not a lot more productive because my coworkers haven’t really kept up, but I spend a hours less time sitting at my desk in my home office. I generally will spend about 10-20 minutes setting up the task, and then have them work on it, and I have them send me an audible alert when they are done writing and reviewing the work, at...
In practice, as opposed to theory, the problems with RCV that I've noticed:
- Antisociality is rewarded. If a candidate's supporters are unlikely to fill in a next-best preference, or likely to fill in an opposite-party preference out of spite, then that candidate is less likely to face opposition within the party.
- Hyper-politicization is rewarded. In a standard election, you check the box for your preferred candidate, and everyone understands this fairly implicitly. In RCV, the process behind strategically ranking your choices is not known to most voters, red
Flagging that I think this back-and-forth is very important.
The "limited serial depth" point seems like the core of Steven's argument for "can't imitation learn how to continual-learn". (If he thinks there's other important parts, i'd be interested to hear it!) And so the more natural statement of the conclusion to me would be "transformers can't do continual learning at runtime, even if they've been trained on trajectories of continual learning"
Fwiw, i feel pretty convinced by Steven's argument here. Human continual learning in fact involves parameter ch...
I was uneasy about "confirmation bias" when I was writing my comment (and momentarily considered "motivated cognition" instead).
No, it's not about complex vs simple situations, it's just about ECL specifically (at least for humans that's the only son-of-CDT issue).
Yeah, I think this is a good argument to give people an intuition, but it doesn't answer the question of "OK, but if you are in the situation, what do you do and why?". FDT supporters (of which I am one, to be clear) do need to answer that.
I cannot find the person right now, but this reminds me of a woman who did some mental thing about not opposing the pain with her will or something and successfully got a dental operation without anaesthesia, with the dentist observing no physiological signs of pain either. She repeated the trick some years later. She had a personal website, complained about not being an academic due to lack of funding (and lack of credentials?), called out various academics in hopes of getting them to pay her - maybe someone reading this known who?
OK, so this is a more UDT-style framing (which I'm sympathetic to). Then the "alternate realities" part, not the "changing the past" part, was more the one targeted at you. But there are definitely people who think about FDT as "changing the past", or at least talk about it in that way, so that's who that clause was targeted at.
Fun fact about tiny black holes: A decently massive black hole (10^13 kg, trillions of years of lifetime) could pass through a human body without killing them: https://arxiv.org/html/2502.09734v2
Well, we are thinking in terms of two facets already if we are thinking e.g. in terms of the (EDT vs CDT)x(updateful vs updateless) 2x2! (which is just decision theory x commitment theory in the framing in the post). So I don't think that's that big of a deal.
If you permit me some speculation, is it possible you're not actually worried about the meaning of "rationality"? (since it's unclear to me why it having two facets would be bad). But instead about the minimization of metaphysical claims like "you are your algorithm", the possibility of alternate real...
You're running a different introspection experiment than we do. You leave steering active during generation:
since the steering vector is still active and increasing the probability of those tokens!
and I also checked your code to be sure, and BatchedLayerSteeringHook steers every position past injection_point, not just at injection_point - including during decode.
That's not how our experiments work - we steer during a segment of past KV cache prefill, and then disable steering during second turn prefill and while the model generates:

Limiting steering to e...
Why is automation logistic?
For comparison, sigmoid of log of <input> is (I think!) very similar to 1 - power-of-<input> i.e. 'failure-rate/can't-be-automated is a power law of <input>'. That's also somewhat intuitive, and appears empirically justified by various evidence, including the decent fit of a constant hazard model to the time-horizons data.
You're taking the key <input> to be effective compute. I still find that somewhat reasonable but I keep feeling disconcerted that so many models here don't appear to account for data. You...
The notable part is that these are representations of concepts that are not obviously part of representing the input or output, but indicate complex internal computation. Eg the intermediate variable during multi hop arithmetic or factual recall. We had anecdata and first principles arguments that something like this ought to exist, but this paper has characterised it far better, and this is important
Epistemic status: Probably a useful canary, not sure about the conclusion.
GPU programming seems not fully automated yet, which may point to the inability of RLVR to overcome data scarcity (the task is fairly niche) even in the face of excellent verifiability.
Naively, a good kernel just returns the correct tensors (i.e. matching a pytorch reference implementation) in the fastest possible time. This makes it a natural target for RLVR, and possible to run a competition where anyone can just submit a kernel with automatic grading.
- The winning submission of the
The first one (bootstrapping) has the issue that if the serial thinking is not 100% perfect, then it will sometimes get mistakes, and then you’re SFT’ing on the mistakes, making the model more confident in those mistakes, and then the next round of serial thinking will incorporate and build on those mistakes. Repeat a billion times in a sealed box, and I think it would spiral into nonsense—it would get dumber not smarter.
Thanks, this is helpful and not an argument i've come across before!
One quick clarification: I presume you're here talking about systemat...
Agreed. Or at least, there are certain psychological factors[1] that make working on abstract alignment problems feel "safer" for some subset of people, myself very much included! On the other hand, these same factors can be "unsafe" to different people or in different contests, and there are plenty of features of other research styles that are psychologically attractive[2].
But I don't really buy the implied add-on "this is psychologically safer for me, therefore it's actually bad," at least not as it applies to myself.
- ^
(e.g. lack of feedback loops can me
AIs probably think a lot about themselves during training. So I don't think you can rely on AIs not thinking about themselves just because you don't train on interp.
Imagine there was an upload technique that could be performed on you without your knowledge, and which produced a "base model" which is just you-on-a-computer, ready to be post-trained.
Then imagine this UploadedYou.safetensors file gets post trained using an gradient descent, in an otherwise fairly standard deep learning post-training paradigm: you wake up in an empty room with a task in front ...
I have watched Death Note several times. Recently I have read the first book in Vorkosigan Saga. And... I still don't really understand this metaphor. Why Death Note characters and not any other clever characters, for example. The best idea I have is that Voldemort here is similar to Light because like Light he pretends to try to make the world pure from rot, but in fact just a psychopath who wishes power.
I don't see how the troll idea worked and not failed. In canon troll was in the school because it is generally is not very well protected and has plenty ...
PSA: Many reasoning models lose access to their CoT between turns.
I was looking into how chat templates render multi-turn interactions, and came across the (surprising to me) fact that it's common practice for reasoning models to discard CoT from prior assistant turns once a new user turn comes in. The DeepSeek documentation has a nice illustration of how this works:
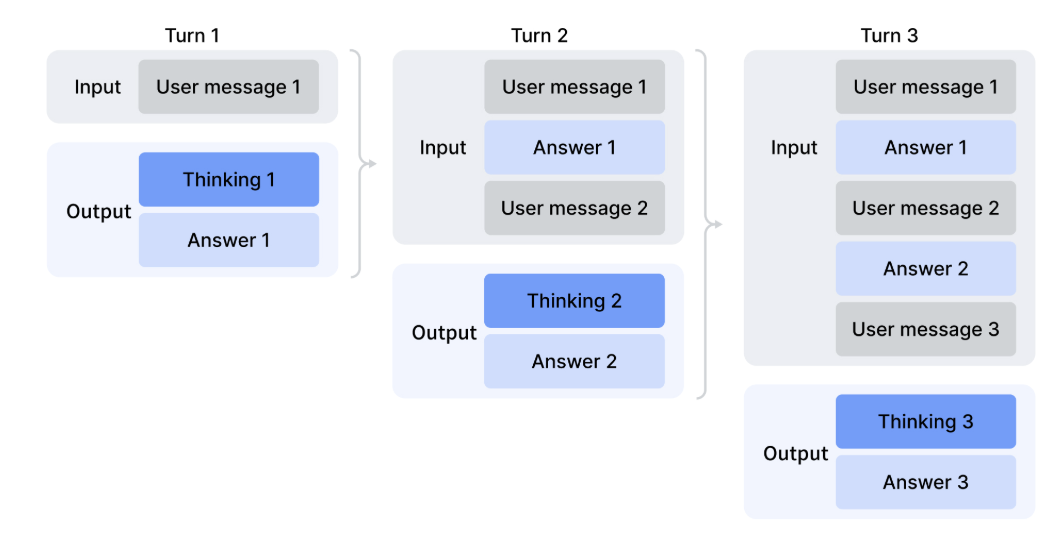
In the Claude API documentation:
...Thinking block context removal
- On earlier Opus/Sonnet models and all Haiku models, thinking blocks from previous turns are removed from context, which can affect
How long did it take before you noticed results?
I attempted a similar maneuver with a product that supposedly forms a silicone layer on the surface of the water that prevents the mosquito larvae accessing oxygen (when they come to the surface to breathe)
But it wasn't very effective and the mosquitoes seemed to be breeding in the buckets quite happily over the ~2 weeks (iirc) I checked the buckets before giving up
Tokens in an environment dominated by LLM powered agents will undergo memetic evolution. Lewontin's 3 sufficient conditions for evolution will be satisfied, specifically:
Differential Fitness: Some patterns of tokens are more likely than others to be regurgitated by an LLM if they become part of its context.
Heritability: If a pattern of tokens are fit, then a copy of those tokens will also be fit.
Variation: As an LLM regurgitates patterns of tokens from its context, it may a) introduce mutations via stochastic sampling and b) combine multiple patterns of to...
Also, there are many spaces in math. The J-space is a topological subspace for example.
You are right.
(But I'm still going with my terminology in my head, since that works better with my other verbal concepts.)
Why would it being a proper (vector) subspace be more interesting?
1) What they've found is a new method for finding meaningful linear directions in the residual stream. This is actually great! Specifically they are able to find linear directions that the model are able to verbalize in a single token, and these also seem to double as internal represen...
Quirrell would be much less likely to make the whole plot just for Hermione spending a couple of weeks in Azkaban. And as he said, he certainly wouldn't get Malfoys into it just for her. And so even if Harry failed to lose, he wouldn't he in a giant debt to Lucius Malfoy (who blames Harry for what happened with Draco). So Quirrell wouldn't need to kill Hermione for Harry to lose debt.
So Harry will never have a reason to have a discussion about Voldemort. He will not have a glimpse on Voldemort cold mind. He would think that the dark lord being alive is jus...
I guess i'm saying that doing that experiments at small scale could very easily cause large inaccuracies, and this is a plausible reason you might be underestimating progress in your 1.1 bucket!
I agree that the left is a big tent and there are always examples of every opinion present in every political movement, but I mostly agree with this take: https://www.transformernews.ai/p/the-left-is-missing-out-on-ai-sanders-doctorow-bender-bores
This doesn't take away from the correct argument that there are prominent leftists who are very vocal about existential AI risk, including really prominent people like Bernie Sanders. But for the most part, the left movement is focusing (as you say yourself) on the more mundane harms. This is not necessarily bad, ...
I think there's a bit of a modus ponens/modus tollens here, where you're saying "surely they wouldn't reallocate time suboptimally!" (so the observed allocation constrains parameters to imply meaningful uplift) while another might conclude "surely the substitutability isn't that high!" (so the observed allocation must be 'suboptimal').
For my part, I think a fair bit (most) of the new code is 'barely useful' in the sense that it's product code, stuff like claude code, cowork, etc. That's actually 'rational' in the sense that it grabs market share and improv...
Yeah, I can see why conditioning a judge on outputs produced by a similarly trained model would make its own output distribution more peaky. I remember mixed evidence on this self-preference point, or at least at the time when we were looking at it it was not the main failure mode. You can measure this in a toy setting where you vary the model family of your judge; it might even be enough to eyeball the outputs to see if same-family gives you worse judgements. But IME other things affect LLMJ output quality more (like managing context, rubric, output format).
Intuitively: if non-code is a strict bottleneck, no amount of coding speedup can raise total code output by more than
Phrasing confused me for a minute here. I think you mean assuming pre-speedup timeshare of non-coding is half, and assuming optimal reallocation of time toward research progress (which is maybe the same as assuming no wasted code, if code is not literally free), then under Leontief substitution you won't observe more than double the code output.
Ty! The point about control and reachability makes sense, and sounds like it might be a part of the right story here. It will still need some tweaks or additions though. For example, we would intuitively expect that a self-driving car without any cameras or sensors isn't entangled enough to do its job. But in terms of reachability, everything is still fine -- the car could give the right set of commands that would get it safely across town, so the safe states are technically reachable.
IMOH LLM verbosity is significantly higher than that of humans. Maybe producing 25-66% more lines of code for the same function. That's when you include docstrings. If you also include skill files and extra/low quality tests that would not have been created by humans, I would not be surprised if, for similar functionalities, LLMs produce 50-100% more lines than humans. For production code, humans may clean the AI-generated code to keep maintenance code low, but not nearly as much for research.
Consider the Bolzano-Weierstrass theorem, which states that a real bounded sequence contains a converging sub-sequence.
There was a time when it didn't appear to me that the BW theorem was true, and I didn't believe in it. Now, it appears to me that it is true, and I believe it is.
The transition from non-belief to belief in the BW theorem wasn't based on appearance, although it coincided: it was based on presentation of rigorous argument (which appeared valid) whose inevitable logical consequence was that the BW theorem was true.
My belief in the BW theorem ...
I disagree.
I don't see how it is not possible for an ASI to program subservient systems with robust oversight aligned to itself. Genes got pretty far in aligning life to there goals despite being dumber and more shortsighted then an average human.
An obvious way to do this is to just not create sub AIs with different goals from the master system to began with. Just copy the master system and send the copy to the next solar system with a fleet of sub-AGI von neumann probes.
It is a copy so it is going to be aligned by default, as long as the copy is accurate ... (read more)