This post is a not a so secret analogy for the AI Alignment problem. Via a fictional dialog, Eliezer explores and counters common questions to the Rocket Alignment Problem as approached by the Mathematics of Intentional Rocketry Institute.
MIRI researchers will tell you they're worried that "right now, nobody can tell you how to point your rocket’s nose such that it goes to the moon, nor indeed any prespecified celestial destination."

Popular Comments
Recent Discussion
Post for a somewhat more general audience than the modal LessWrong reader, but gets at my actual thoughts on the topic.
In 2018 OpenAI defeated the world champions of Dota 2, a major esports game. This was hot on the heels of DeepMind’s AlphaGo performance against Lee Sedol in 2016, achieving superhuman Go performance way before anyone thought that might happen. AI benchmarks were being cleared at a pace which felt breathtaking at the time, papers were proudly published, and ML tools like Tensorflow (released in 2015) were coming online. To people already interested in AI, it was an exciting era. To everyone else, the world was unchanged.
Now Saturday Night Live sketches use sober discussions of AI risk as the backdrop for their actual jokes, there are hundreds...
I agree with RL agents being misaligned by default, even more so for the non-imitation-learned ones. I mean, even LLMs trained on human-generated data are misaligned by default, regardless of what definition of 'alignment' is being used. But even with misalignment by default, I'm just less convinced that their capabilities would grow fast enough to be able to cause an existential catastrophe in the near-term, if we use LLM capability improvement trends as a reference.
The history of science has tons of examples of the same thing being discovered multiple time independently; wikipedia has a whole list of examples here. If your goal in studying the history of science is to extract the predictable/overdetermined component of humanity's trajectory, then it makes sense to focus on such examples.
But if your goal is to achieve high counterfactual impact in your own research, then you should probably draw inspiration from the opposite: "singular" discoveries, i.e. discoveries which nobody else was anywhere close to figuring out. After all, if someone else would have figured it out shortly after anyways, then the discovery probably wasn't very counterfactually impactful.
Alas, nobody seems to have made a list of highly counterfactual scientific discoveries, to complement wikipedia's list of multiple discoveries.
To...
Bowler's comment on Wallace is that his theory was not worked out to the extent that Darwin's was, and besides I recall that he was a theistic evolutionist. Even with Wallace, there was still a plethora of non-Darwinian evolutionary theories before and after Darwin, and without the force of Darwin's version, it's not likely or necessary that Darwinism wins out.
...But Wallace’s version of the theory was not the same as Darwin’s, and he had very different ideas about its implications. And since Wallace conceived his theory in 1858, any equivalent to
Le coût d’opportunité des délais en développement technologique
Par Nick Bostrom
Abstract: Grâce à des technologies avancées, on pourrait maintenir une très grande quantité de personnes menant des vies heureuses dans la région accessible de l’univers. Chaque année où la colonisation de l’univers ne se déroule pas représente un coût d’opportunité; des vies qui valent d’êtres vécues ne peuvent être réalisées. D’après des estimations plausibles, ce coût est extrêmement élevé. Mais la leçon pour les utilitaristes n’est pas qu’il faut maximiser la cadence du développement technologique, mais sa sécurité. Autrement dit, il faut maximiser la probabilité que la colonisation se déroule.
Le rythme de perte de vies potentielles
En ce moment, des soleils illuminent et réchauffent des pièces vides et des trous noirs absorbent une portion de l’énergie inutilisée du cosmos. Chaque minute,...
Is this a translation of Bostrom's article? If yes, could you please make this more explicit (maybe as a first paragraph in the text, in English), and include a link to the original?
Hey Jacques, sure, I'd be happy to chat!
Crosspost from my blog.
If you spend a lot of time in the blogosphere, you’ll find a great deal of people expressing contrarian views. If you hang out in the circles that I do, you’ll probably have heard of Yudkowsky say that dieting doesn’t really work, Guzey say that sleep is overrated, Hanson argue that medicine doesn’t improve health, various people argue for the lab leak, others argue for hereditarianism, Caplan argue that mental illness is mostly just aberrant preferences and education doesn’t work, and various other people expressing contrarian views. Often, very smart people—like Robin Hanson—will write long posts defending these views, other people will have criticisms, and it will all be such a tangled mess that you don’t really know what to think about them.
For...
I guess in the average case, the contrarian's conclusion is wrong, but it is also a reminder that the mainstream case is not communicated clearly, and often exaggerated or supported by invalid arguments. For example:
- it's not that "dieting doesn't work", but that people naively assume that dieting is simple and effective ("if you just stop eating chocolate and start exercising for one hour every day, you will certainly lose weight", haha nope), even when the actual weight-loss research shows otherwise;
- it's not that "medicine doesn't improve health", but whi
I've seen a lot of news lately about the ways that particular LLMs score on particular tests.
Which if any of those tests can I go take online to see how my performance on them compares to the models?
https://www.equistamp.com/evaluations has a bunch, including an alignment knowledge one they made.
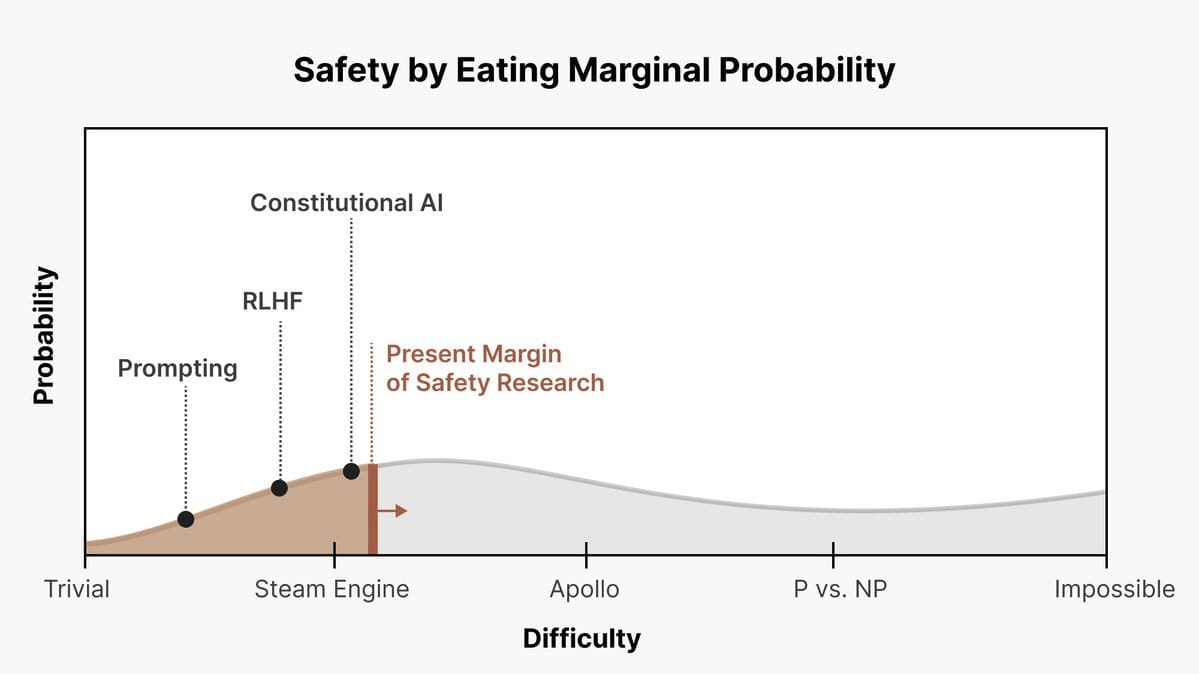
Chris Olah recently released a tweet thread describing how the Anthropic team thinks about AI alignment difficulty. On this view, there is a spectrum of possible scenarios ranging from ‘alignment is very easy’ to ‘alignment is impossible’, and we can frame AI alignment research as a process of increasing the probability of beneficial outcomes by progressively addressing these scenarios. I think this framing is really useful, and here I have expanded on it by providing a more detailed scale of AI alignment difficulty and explaining some considerations that arise from it.
The discourse around AI safety is dominated by detailed conceptions of potential AI systems and their failure modes, along with ways to ensure their safety. This article by the DeepMind safety team provides an overview of some...
Behavioural Safety is Insufficient
Past this point, we assume following Ajeya Cotra that a strategically aware system which performs well enough to receive perfect human-provided external feedback has probably learned a deceptive human simulating model instead of the intended goal. The later techniques have the potential to address this failure mode. (It is possible that this system would still under-perform on sufficiently superhuman behavioral evaluations)
There are (IMO) plausible threat models in which alignment is very difficult but we don't n...
Please don’t feel like you “won’t be welcome” just because you’re new to ACX/EA or demographically different from the average attendee. You'll be fine!
Exact location: https://plus.codes/8CCGPRJW+V8
We meet on top of a small hill East of the Linha d'Água café in Jardim Amália Rodrigues. For comfort, bring sunglasses and a blanket to sit on. There is some natural shade. Also, it can get quite windy, so bring a jacket.
(Location might change due to weather)
Please don’t feel like you “won’t be welcome” just because you’re new to ACX/EA or demographically different from the average attendee. You'll be fine!
Exact location: https://plus.codes/8CCGPRJW+V8
We meet on top of a small hill East of the Linha d'Água café in Jardim Amália Rodrigues. For comfort, bring sunglasses and a blanket to sit on. There is some natural shade. Also, it can get quite windy, so bring a jacket.
(Location might change due to weather)
