How does it work to optimize for realistic goals in physical environments of which you yourself are a part? E.g. humans and robots in the real world, and not humans and AIs playing video games in virtual worlds where the player not part of the environment. The authors claim we don't actually have a good theoretical understanding of this and explore four specific ways that we don't understand this process.

Popular Comments
Recent Discussion
Q. "Can you hold the door?" A. "Sure."
That's straightforward.
Q. "Can you play the violin at my wedding next year?" A. "Sure."
Colloquial language would imply not only am I willing and able to do this, I already know how to play the violin. Sometimes, what I want to answer is that I don't know how to play the violin, I'm willing to learn, but you should know I currently don't know.
Which I can say, it just takes more words.
If you're working at the intersection between cryptogrpahy, secuity and AI, consider joining this upcoming workshop:
Foresight's AGI: Cryptography, Security & Multipolar Scenarios Workshop
May 14-15, all-day
The Institute, Salesforce Tower, San Francisco
Goals
To help AI development benefit humanity, Foresight Institute has held various workshops over the past years and launched a Grants Program that funds work on AI security risks, cryptography tools for safe AI, and safe multipolar AI scenarios. Our 2024 workshop invites leading researchers, entrepreneurs, and funders in this growing space to explore new tools and architectures that help humans and AIs cooperate securely. In addition to short presentations, working groups, and project development, we offer mentorship hours, open breakouts, and speaker & sponsor gatherings.
Questions we’ll address include
- Which challenges in AI alignment, AI security and AI coordination (in particular
I'll be there! Talk to me about boundaries and coordination/Goodness
There's also the problem of: what do you mean by "the human"? If you make an empowerment calculus that works for humans who are atomic & ideal agents, it probably breaks once you get a superintelligence who can likely mind-hack you into yourself valuing only power. It never forces you to abstain from giving up power, since if you're perfectly capable of making different decisions, but you just don't.
Another problem, which I like to think of as the "control panel of the universe" problem, is where the AI gives you the "control panel of the universe", bu...
I think this is also what I was confused about -- TurnTrout says that AIXI is not a shard-theoretic agent because it just has one utility function, but typically we imagine that the utility function itself decomposes into parts e.g. +10 utility for ice cream, +5 for cookies, etc. So the difference must not be about the decomposition into parts, but the possibility of independent activation? but what does that mean? Perhaps it means: The shards aren't always applied, but rather only in some circumstances does the circuitry fire at all, and there are circums...
ACX recently posted about the Rootclaim Covid origins debate, coming out in favor of zoonosis. Did the post change the minds of those who read it, or not? Did it change their judgment in favor of zoonosis (as was probably the goal of the post), or conversely did it make them think Lab Leak was more likely (as the "Don't debate conspiracy theorists" theory claims)?
I analyzed the ACX survey to find out, by comparing responses before and after the post came out. The ACX survey asked readers whether they think the origin of Covid is more likely natural or Lab Leak. The ACX survey went out March 26th and was open until about April 10th. The Covid origins post came out March 28th, and the highlights on April...
Is a lot of the effect not "people who read ACX trust Scott Alexander"? Like, the survey selects for most "passionate" readers, those willing to donate their free time to Scott for research with ~nothing in return. Him publicly stating on his platform "I am now much less certain of X" is likely to make that group of people be less certain of X?
Summary
- We present a method for performing circuit analysis on language models using "transcoders," an occasionally-discussed variant of SAEs that provide an interpretable approximation to MLP sublayers' computations. Transcoders are exciting because they allow us not only to interpret the output of MLP sublayers but also to decompose the MLPs themselves into interpretable computations. In contrast, SAEs only allow us to interpret the output of MLP sublayers and not how they were computed.
- We demonstrate that transcoders achieve similar performance to SAEs (when measured via fidelity/sparsity metrics) and that the features learned by transcoders are interpretable.
- One of the strong points of transcoders is that they decompose the function of an MLP layer into sparse, independently-varying, and meaningful units (like neurons were originally intended to be before superposition was discovered).
Hey Jacob + Philippe,
Hope you all don't mind but we put up layer 8 of your transcoders onto Neuronpedia, with ~22k dashboards here:
https://neuronpedia.org/gpt2-small/8-tres-dc
Each dashboard can be accessed at their own url:
https://neuronpedia.org/gpt2-small/8-tres-dc/0 goes to feature index 0.
You can also test each feature with custom text:
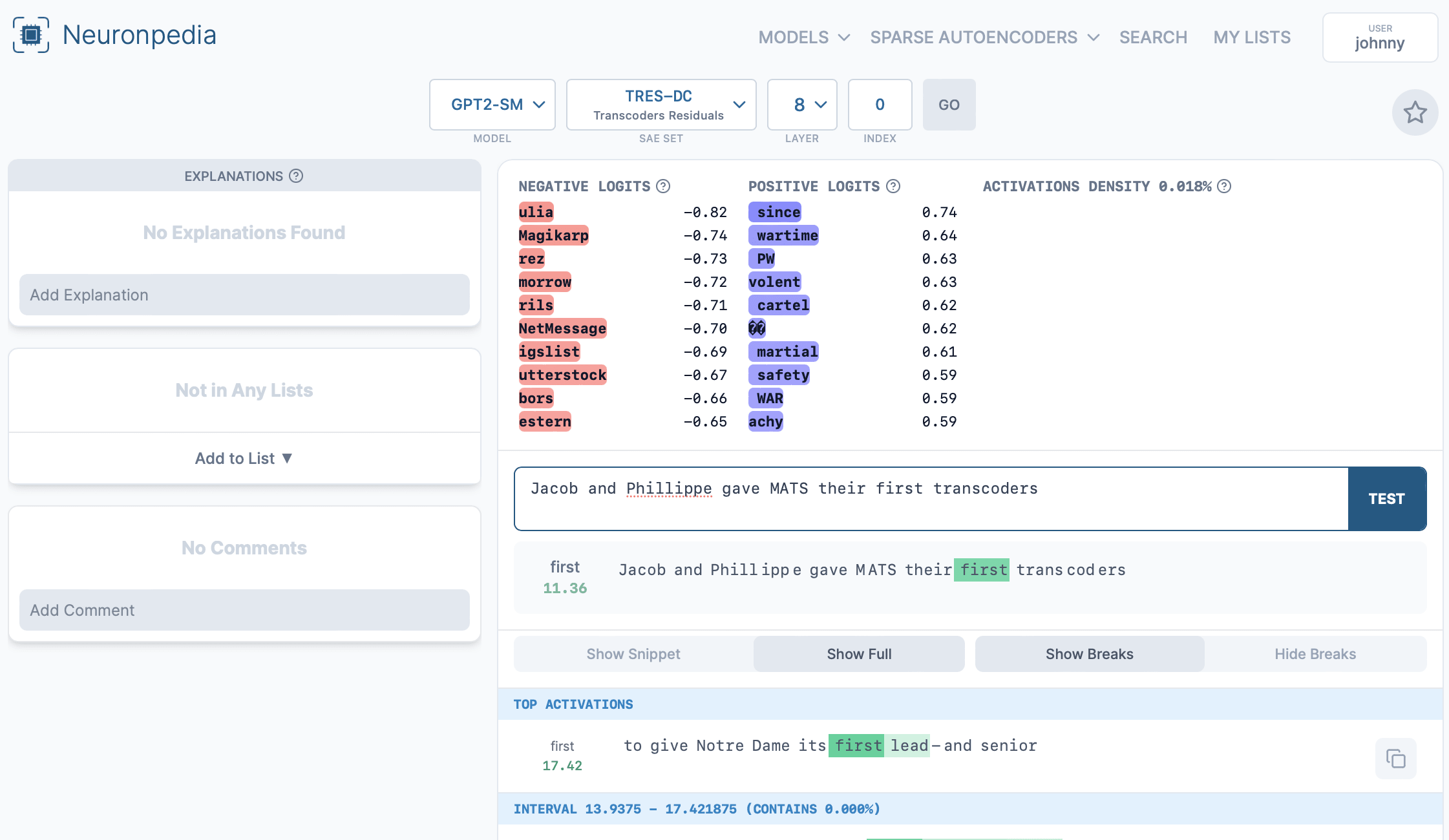
Or search all features at: https://www.neuronpedia.org/gpt2-small/tres-dc
An example search: https://www.neuronpedia.org/gpt2-small/?sourceSet=tres-dc&selectedLayers=[]&sortIndexes=[]&q=the%20cat%20sat%20on%20...
You can! Just go to the all-posts page, sort by year, and the highest-rated shortform posts for each year will be in the Quick Takes section:
2024:

2023:

2022:

Abstract:
Inspired by the Kolmogorov-Arnold representation theorem, we propose Kolmogorov-Arnold Networks (KANs) as promising alternatives to Multi-Layer Perceptrons (MLPs). While MLPs have fixed activation functions on nodes ("neurons"), KANs have learnable activation functions on edges ("weights"). KANs have no linear weights at all -- every weight parameter is replaced by a univariate function parametrized as a spline. We show that this seemingly simple change makes KANs outperform MLPs in terms of accuracy and interpretability. For accuracy, much smaller KANs can achieve comparable or better accuracy than much larger MLPs in data fitting and PDE solving. Theoretically and empirically, KANs possess faster neural scaling laws than MLPs. For interpretability, KANs can be intuitively visualized and can easily interact with human users. Through two examples in mathematics and physics, KANs are shown to be useful collaborators helping scientists (re)discover mathematical and physical laws. In summary, KANs are promising alternatives for MLPs, opening opportunities for further improving today's deep learning models which rely heavily on MLPs.
I'm not so sure. You might be right, but I suspect that catastrophic forgetting may still be playing an important role in limiting the peak capabilities of an LLM of given size. Would it be possible to continue Llama3 8B's training much much longer and have it eventually outcompete Llama3 405B stopped at its normal training endpoint?
I think probably not? And I suspect that if not, that part (but not all) of the reason would be catastrophic forgetting. Another part would be limited expressivity of smaller models, another thing which the KANs seem to help with.
It also suggests that there might some sort of conservation law for pain for agents.
Conservation of Pain if you will
