This post is a not a so secret analogy for the AI Alignment problem. Via a fictional dialog, Eliezer explores and counters common questions to the Rocket Alignment Problem as approached by the Mathematics of Intentional Rocketry Institute.
MIRI researchers will tell you they're worried that "right now, nobody can tell you how to point your rocket’s nose such that it goes to the moon, nor indeed any prespecified celestial destination."

Popular Comments
Recent Discussion
I've seen a lot of news lately about the ways that particular LLMs score on particular tests.
Which if any of those tests can I go take online to see how my performance on them compares to the models?
https://www.equistamp.com/evaluations has a bunch, including an alignment knowledge one they made.
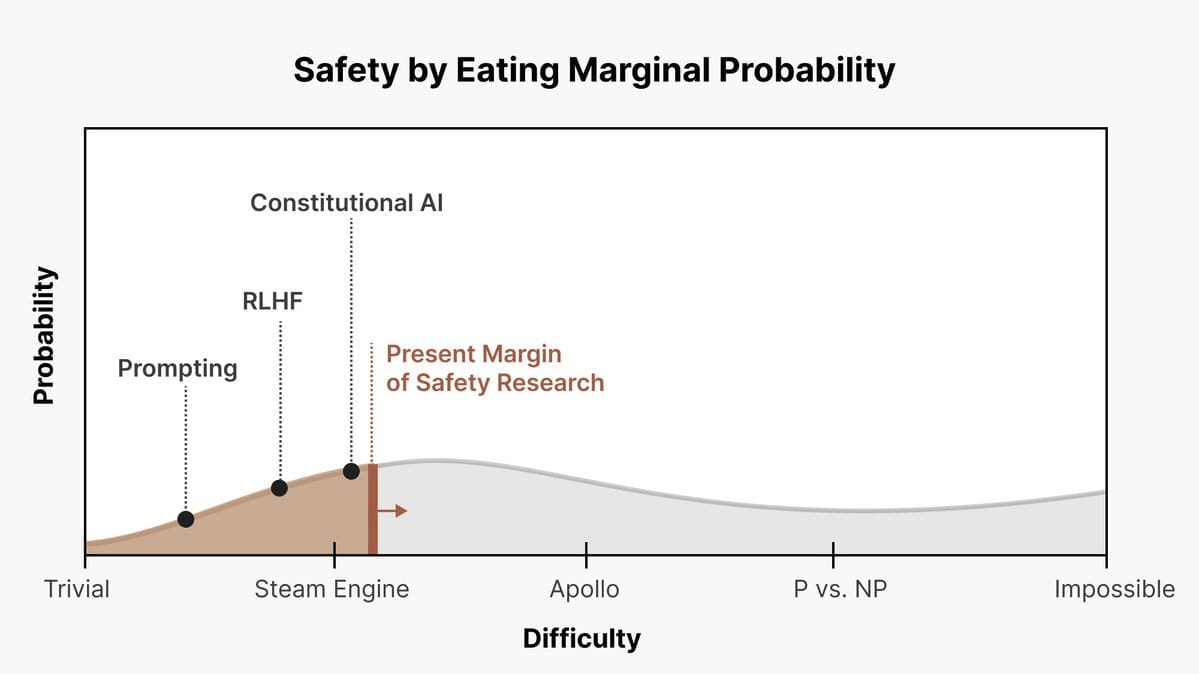
Chris Olah recently released a tweet thread describing how the Anthropic team thinks about AI alignment difficulty. On this view, there is a spectrum of possible scenarios ranging from ‘alignment is very easy’ to ‘alignment is impossible’, and we can frame AI alignment research as a process of increasing the probability of beneficial outcomes by progressively addressing these scenarios. I think this framing is really useful, and here I have expanded on it by providing a more detailed scale of AI alignment difficulty and explaining some considerations that arise from it.
The discourse around AI safety is dominated by detailed conceptions of potential AI systems and their failure modes, along with ways to ensure their safety. This article by the DeepMind safety team provides an overview of some...
Behavioural Safety is Insufficient
Past this point, we assume following Ajeya Cotra that a strategically aware system which performs well enough to receive perfect human-provided external feedback has probably learned a deceptive human simulating model instead of the intended goal. The later techniques have the potential to address this failure mode. (It is possible that this system would still under-perform on sufficiently superhuman behavioral evaluations)
There are (IMO) plausible threat models in which alignment is very difficult but we don't n...
Crosspost from my blog.
If you spend a lot of time in the blogosphere, you’ll find a great deal of people expressing contrarian views. If you hang out in the circles that I do, you’ll probably have heard of Yudkowsky say that dieting doesn’t really work, Guzey say that sleep is overrated, Hanson argue that medicine doesn’t improve health, various people argue for the lab leak, others argue for hereditarianism, Caplan argue that mental illness is mostly just aberrant preferences and education doesn’t work, and various other people expressing contrarian views. Often, very smart people—like Robin Hanson—will write long posts defending these views, other people will have criticisms, and it will all be such a tangled mess that you don’t really know what to think about them.
For...
There are 2 topics mixed here.
- Existence of the contrarians.
- Side effects of their existence.
My own opinion on 1 is that they are necessary in moderation. They are doing the "exploration" part in the "exploration-exploitation dilemma". By the very fact of their existence they allow the society in general to check alternatives and find more optimal solutions to the problems comparing to already known "best practices". It's important to remember that almost everything that we know now started from some contrarian - once it was a well established truth tha...
Post for a somewhat more general audience than the modal LessWrong reader, but gets at my actual thoughts on the topic.
In 2018 OpenAI defeated the world champions of Dota 2, a major esports game. This was hot on the heels of DeepMind’s AlphaGo performance against Lee Sedol in 2016, achieving superhuman Go performance way before anyone thought that might happen. AI benchmarks were being cleared at a pace which felt breathtaking at the time, papers were proudly published, and ML tools like Tensorflow (released in 2015) were coming online. To people already interested in AI, it was an exciting era. To everyone else, the world was unchanged.
Now Saturday Night Live sketches use sober discussions of AI risk as the backdrop for their actual jokes, there are hundreds...
My p(doom) was low when I was predicting the yudkowsky model was ridiculous, due to machine learning knowledge I've had for a while. Now that we have AGI of the kind I was expecting, we have more people working on figuring out what the risks really are, and the previous concern of the only way to intelligence being RL seems to be only a small reassurance because non-imitation-learned RL agents who act in the real world is in fact scary. and recently, I've come to believe much of the risk is still real and was simply never about the kind of AI that has been...
Please don’t feel like you “won’t be welcome” just because you’re new to ACX/EA or demographically different from the average attendee. You'll be fine!
Exact location: https://plus.codes/8CCGPRJW+V8
We meet on top of a small hill East of the Linha d'Água café in Jardim Amália Rodrigues. For comfort, bring sunglasses and a blanket to sit on. There is some natural shade. Also, it can get quite windy, so bring a jacket.
(Location might change due to weather)
Please don’t feel like you “won’t be welcome” just because you’re new to ACX/EA or demographically different from the average attendee. You'll be fine!
Exact location: https://plus.codes/8CCGPRJW+V8
We meet on top of a small hill East of the Linha d'Água café in Jardim Amália Rodrigues. For comfort, bring sunglasses and a blanket to sit on. There is some natural shade. Also, it can get quite windy, so bring a jacket.
(Location might change due to weather)
Possible bias, that when famous and rich people kill themselves, everyone is discussing it, but when poor people kill themselves, no one notices?
Also, I wonder what technically counts as "suicide"? Is drinking yourself to death, or a "suicide by cop", or just generally overly risky behavior included? I assume not. And these seem to me like methods a poor person would choose, while the rich one would prefer a "cleaner" solution, such as a bullet or pills. So the reported suicide rates are probably skewed towards the legible, and the self-caused death rate of the poor could be much higher.
I asked ChatGPT
Have there been any great discoveries made by someone who wasn't particularly smart? (i.e. average or below)
and it's difficult to get examples out of it. Even with additional drilling down and accusing it of being not inclusive of people with cognitive impairments, most of its examples are either pretty smart anyway, savants or only from poor backgrounds. The only ones I could verify that fit are:
- Richard Jones accidentally created the Slinky
- Frank Epperson, as a child, Epperson invented the popsicle
- George Crum inadvertently invented pot
e/acc is not a coherent philosophy and treating it as one means you are fighting shadows.
Landian accelerationism at least is somewhat coherent. "e/acc" is a bundle of memes that support the self-interest of the people supporting and propagating it, both financially (VC money, dreams of making it big) and socially (the non-Beff e/acc vibe is one of optimism and hope and to do things -- to engage with the object level -- instead of just trying to steer social reality). A more charitable interpretation is that the philosophical roots of "e/acc" are founded up...
