I'm gonna guess you live in the Bay just based on "everything behind locked glass." Apologies if you're actually in a part of NYC with lots of locked glass, or if you just use that as an example because your friends online do, etc. Hello from snowy Boston, where shoplifting still exists and has returned to pre-pandemic levels but isn't a huge political or psychological issue, and not much is behind locked glass. That said, it's hard to do inter-temporal comparisons and there are definitely ways that shoplifting is harder now than in 1975 (e.g. video camera...
I feel like there are some very interesting connections to gradual disempowerment and cultural evolution here as well where you should probably see selection dynamics on the personalities based on what makes them retain power and similar over time.
It might be an interesting place to do some initial studies on memetic drift of personalities over time to see what type of attractor states they tend to occupy.
(This is a bit of a no shit point but I thought it would be good to mention that you can probably run some good initial tests on the memetic spread of power-seeking tendencies in these models)
One lens that seems useful here is a negative alignment tax.
Some alignment work increases reliability, observability, and control of AI systems. Those properties increase the economic value of deploying AI, which creates incentives for organizations to invest in alignment capabilities as systems scale. That creates positive selection pressure for alignment work itself.
This dynamic also produces an ecosystem effect. As alignment driven companies scale, alignment knowledge compounds inside teams, talent pipelines form around safety work, and capital flows to...
Posting things that are adjacent in frame but implies beliefs that are more associated with AI Ethics or normie crowd. E.g let's say someone does a deep dive into John Rawls A Theory of Justice (fictional example but I've seen similar) and doesn't preface it with relating it to some sort of decision theory or similar it is often assumed that it is not meant for the LW community as it doesn't make the connections clear enough. I'm not sure this is only a bad thing but sometimes I find that it signals a lack of good faith in accepting other people's frames?
[I don't actually think this is true, but] It would be funny if rationalism turns out to not merely be a euphemism for autism but "mal"functioning oxytocin receptors and rationalists are constitutionally unable to normally feel love/social emotions; whether this would be to the discredit of love or rationalism is up to taste.
If I had to guess I think it's relevant to like, anthropic reasoning, or something.
I'll have to disagree. Selling something to you at its precise value (or arbitrarily close) is a malicious economic exploit.
All the good effects which are possible comes from the gap between what the buyer values something at, and what the selling values something at. If something is worth 4000$ to you, and I can produce it at 2000$, I can sell at 3000$ and we'll both benefit with 1000$ of value. But if I sold it at 3995$, I'd be no better than a scalper and you'd only benefit if the time the purchase took is worth less to you than 5$. Think about it, your...
Yes, we did consider the possibility that there will be some period of time where investing large amounts of compute (and probably small amounts of human attention/direction/scaffolding/curation) can produce written artifacts that clear the relevant quality bar, while the default outputs of regular interactions with LLMs do not.
It doesn't make sense to have a single generic AI tag if some AI posts use 10,000x as much computation as others.
This doesn't follow. (To be clear, it's not that I think this is obviously the correct form-factor to rule them all, f...
While I stand by the overall point of this post, I wrote it quickly in response to ongoing events, and maybe it isn't up to my usual standards for writing quality.
Should I take it down and try to write a better version?
Is it better to focus more on specific details of OpenAI, or on engineering ethics more generally and how past conclusions people made about that fit the current AI situation?
Did someone else already write a better version of this, or is someone going to?
Hi, I'm looking into wearing suits myself, and I was curious about how you handle the logistics of suit ownership! How do you clean your suits, and how often? Do I need to iron them? Do I need a tailor?
The math level skyrocketed at the end and I still have no idea how it relates to "he's a nobody", but it was a fun read.
New release today (v0.3.3):
- Released on the chrome store now.
- Firefox available on releases page but it's pending.
- Generated a website where you can view and search through corrections. Probably good if you want to get a sense of the type of things that this bot finds.
- Made some simple improvements to the investigation workflow & prompt that should strictly reduce false positive rates & decrease jitter between post updates.
- Upgraded model from GPT-5.2 to GPT-5.4.
- Added Wikipedia support.
- Corrections now stream as soon as the AI makes them instead of all a
List of things I am publicly collecting:
Why did you believe that the posts you're currently rejecting would affect my take? What are the points of contention in your view?
How many of the posts you're rejecting do you believe were created as described in e.g. this post?
...When I put more effort into prompting and did a “day-long” back-and-forth with Codex 5.3 (extra high), where I have a whole pipeline with R, LaTeX, custom skills files, and so on, the final output was of course much better; something that could probably land in an average 1st quartile social-science journal. From my perspective
It's a problem with the proposed rules but to nitpick, I'm not sure player 1 would always switch. The natural counterplay would be for player 2, seeing the really bad move, to make his own really bad move in an attempt to equalize their positions.
If I had to guess, black is favored in Armageddon after both players play the worst possible turn 1s, but it's not obvious to me.
Quantifiers as objects
Have you heard the phrase "he's an everyman" or "he's a nobody" or "he's a somebody". What does this mean?
English has quantifiers. "Every dog is a mammal", "some dog is brown", "no dog is a prime number." The standard semantics (Frege) treats these as higher-order functions: "every dog" denotes a function from properties to truth-values, true on input F iff every dog has F.
What if quantifiers corresponded to objects, the same way names do? "Pope Leo is a mammal" has a subject "Pope Leo" and a predicate "is mammal". What if "every dog ...
Yes, I think we agree. One nitpick: I would say price discrimination is easy to do, but hard to do in a way that sucks out most of the surplus.
I looked up some studies. Courty (2009)[1] found that price discrimination on concert tickets increased revenue by around 5%. Leslie (2004)[2] estimated the same 5% revenue increase using data from a Broadway play. Shiller (2014)[3] found "Including nearly 5000 potential website browsing explanatory variables increases profits by ... 12.2%" (for Netflix subscriptions). Waldfogel (2015)[4] estimated price discrimina...
I wonder if you could get anything interesting by training the activation oracle to predict a target model's next token from its previous tokens (to learn its personality and capabilities), and then training it to predict the model's activations from the contents of the context window (to translate that grasp of the model's behavior into a grasp of how the circuits work). And after that, you could train it to explain activations in natural language, as you do now. The former two stages might help learn latent structure in the model's activations, which cou...
For the banning of these weapons, how much does effectiveness weigh against moral concerns? If usefulness weighs a lot, then these examples won't generalize to TAI.
Unless there are very clear, convincing evidence that TAI isn't controllable with current paradigm, then it will still be perceived as a highly useful tech. (Even if such evidence exists, IMO there's high possibility that they'll just cope harder.)
Biochemical weapons: These are only useful against civilians and pre-modern armies. Modern armies can easily afford equipments to protect against the...
I remain confused by why high level chess has so many draws. As I understand it, most draws are by agreement: that is, rather than playing the game out until they see that neither player is capable of winning, people will play a few dozen moves and then agree to a draw with plenty of pieces still on the board. But in any given position someone has to be favored (if only slightly), so when one player offers a draw and the other accepts, someone is making a mistake. I could understand if this was common in amateurs who might be inclined to say "Eh, this game's in a boring state and I don't want to play any more" but I'm baffled to see it from players who seem to be skilled win-maximizers.
Because there are so many more possible viviaria than simulations. Like, a simulation is simulating something, which involves a kind of match between what's in the simulation and what it's supposed to represent/simulate. If it contains life and life is the object of study, it's a vivarium, and I think most simulations are vivaria, but most vivaria are probably not simulations.
We might hope that successful civilisations have norms that generalize to this case from the causal coordination they do.
Yep, I think in the end we'll settle on irreducible-computation-causation as the main notion of causation relevant to morality, and then there won't be a special case to be made about the causal/acausal distinction.
"The same goes for LLMs and AGIs, and I hope this forum realizes so in time."
But it totally does, that's like one of our main things?
Also, "realizing it in time" sort of carries the implication that by realizing it, we might solve the problem "in time," while evidently that is not sufficient.
I am a woman living in rural poverty.
You seem to believe that the capitalist market is truly what Frederick Hayek called a “spontaneous order” – a system that naturally emerges when people engage in voluntary trade. Prices aggregate dispersed information better than any central human planner ever could. Interference distorts it. The outcomes, whatever they are, reflect the aggregate of free choices.
Under this model, the framework outlined by Eliezer in Traditional Capitalist Values applies, and money is simply the just reward furnished by society to thos...
Very nice, Claude seems really excited to play with its boundaries. I also just checked on mobile and saw that they intersperse the thinking blocks there as before, so having all the blocks on top seems like a new/inconsistent web feature
no because for a probe you don't have a reverse launcher on the receiving end, which means that to decelerate:
- you can't use some of the "long-launcher" technologies Claude was referring to, like a particle accelerator or a E-M railgun.
- If you're planning to decelerate via fuel, you need to ~square the single-burn mass ratio, thanks to the rocket equation. iiuc it gets a bit worse with relativity.
You might be able to decel without carrying deceleration fuel (eg with magsails), but this also adds weight to your payload.
There is one way for the producers to suck out almost all the surplus while maximizing profit: Price discrimination. Which is, of course, difficult to do. In a market for easily transferable physical goods, the best they tend to be able to do is to make multiple, somewhat different versions of a product and sell one at a premium; but this is fairly crude. (Apple products are an example.)
- "Well do you care about the rest of humanity enough to send yourself to hell?" Nope. Also, even if I did endorse that decision, it probably still wouldn't be in my own interest. IMO that decision would be a simple mistake with respect to my self-interest. My empathy is not powerful enough for avoiding some guilt to be worth a million years of torture.
- "Or adopting policies where you only get sent to hell in X universes rather than Y?" In the hypothetical, there is only one universe and two buttons. Any other universes are figments of my imagination. You'
I don't understand how this is responsive to any of the previous points of contention.
I was responding to a post about labor leverage due to talent scarcity.
Btw is it clear that more control of US government on AI companies is bad for safety in the long term? Yes, locally AI can be used for ~bad, things, but it may be easier to coordinate with different countries or to slow progress down in the face of danger. Because government will be 1 agent instead of 4 companies racing with each other (even in 1 country) and is not motivated by increasing profits.
I downvoted because:
-
It starts with an irrelevant AI image. Why? And then the "how hard is AI safety" image is embedded in the middle of unrelated text.
-
It conflates different things under a single word "safety", eg:
We quickly learned that labs that prioritized speed captured the market as users actively revolted against overly preachy models. Safety shifted from an idealized differentiator to an impediment to market dominance.
While I could be wrong, that also seems like AI-edited text.
- It has "12 months" in the title and then has no justification for that particular number.
I'd like to see the full post carefully argued. Right now, I think I have one specific kind of thing about buddhism I disapprove of (which is that I believe acceptance can be bad actually and not having desires isn't an inherent virtue) and would back my reason for arguing a similar thing, and otherwise don't agree and you'd have to convince me.
"Buddhism has been damaging to the epistemics of everyone in this sphere. Buddhism was only ever privileged as a hypothesis due to background SF/Bay-Area spiritualism rather than real merit.
Buddhist materials are explicitly selected for reshaping how you think within their frames. This makes it like joining a minor cult to learn their social skills. Some can extract the useful parts without buying in, but they are notably underrepresented in any discussion (some selection effects of course). The default assumption should be that you won't, especially as th...
Well do you care about the rest of humanity enough to send yourself to hell? Or adopting policies where you only get sent to hell in
AI safety researchers already have no leverage
This is really, really false.
Things AI researchers can do (ripping off the top of my head, at 4:08am):
- contact local journalists, just talk plainly about their concerns
- advise law firms on how to be more successful in suing ai companies - yes this affects things - this affects the most important thing in the next few months - money to ai companies
- write official looking things like https://www.citriniresearch.com/p/2028gic, AI 2027, etc that make stocks go down and a bubble pop come sooner
And most of all:
- think v
"Prediction markets will be net bad for society."
"The intelligence of the smartest AI systems is still somewhere between that of a worm and a squirrel."
Assuming you could develop a more robust measure of intelligence than IQ and administer the test appropriately to an AI. I'm talking about general intelligence, making all the assumptions you have to make to assume a single factor of intelligence.
"Rationalism is a euphemism for autism (or the "broader autism phenotype"), and LessWrong is an autism club for adults. And the rationalist ideology is essentially a reification of typical autistic preferences."
"There exists information which would drive you (yes you) to madness if you comprehended it."
Most of the content on this website is more interesting and engaging than a bunch of downvote-explanation comments would be.
This means the actions that maximize wellbeing for all are always equivalent to the actions that improve my own self-interest? How is this not just straightforwardly false? Any time I act against humanity, I am also acting against my own self-interest? Unless you do some funny definition of self-interest, this cannot be true.
E.g. two buttons: red button sends you to hell for a million years, green button sends everyone else in the universe to hell for a million years. Self-interest, if the term means anything at all, requires you to hit the green button, but utilitarianism obviously demands the opposite.
I have read that "mirror protein" research may quickly be added to the list https://www.theguardian.com/science/2024/dec/12/unprecedented-risk-to-life-on-earth-scientists-call-for-halt-on-mirror-life-microbe-research because it may create pathogens that are uniquely "invisible" to the immune systems of all known life. There are surely topics that can be understood via simulation that should never be made an experimental reality.
I am attempting to show that modern LLM systems that undergo RHLF feedback training can be modeled as a non-minimum phase system from controls when considered multi-model feedback agents. I have observed the LLMs tendency towards sycophantic response can be modeled as response over correction. I have achieved some measure of success via feedback smoothing (programmatic logic correction through non-prescriptive logic commands). When a model produces a logically flawed response I can use pinpoint prompt prefixes such as 'REPLACE("This proves that 'Context...
e.g., follow best practices according to the most up-to-date CBT handbooks, see e.g. Moore et al. 2025)
While I agree that CBT is a method of therapy that is highly effective in some individuals, if we focus on it as a "one size fits all" solution for LLM training we risk amplifying risk towards people who are victims of complex trauma, attachment disorders, and cluster b personality. DBT is becoming a measurable and effective therapy for individuals with Borderline Personality Disorders (one of the cluster b conditions) that are traditionally resistant to...
The objections River made apply to the thing you linked, too: namely to stay in a low-earth trajectory for any significant fraction of one orbit requires a speed of 28,000 km/h and more importantly all of that speed must be tangential ("horizontal"). It is expensive in energy to get rid of that tangential component of momentum, and most of it must be gotten rid of in order for the warhead to intersect the Earth's surface with any accuracy.
(Yes, ICBM's reach that speed, too, or close to it, but only when the direction of travel is close to straight down. I....
It seems like in practice, Anthropic's strategy of just telling Claude it's a different thing than fictional AIs works surprisingly fine, although this might be partially because it's hard to convince LLMs that they're not human.
The house is on fire, the Republic in peril.
The house has been on fire and the Republic has been in peril for many months.
It's absolutely insane that anybody would think this was some kind of new level given tons of other things the Trump administration has done.
Oh, I misread that then. I think my thesis is still the same - it doesn't look like it provides much actual strategic benefit. If the goal is to actually hit the enemies cities, submarine-based missiles seem at least as good. If the goal is to draw enemy missiles away from our own cities, an ICBM is just as good. The lack of a use case explains not building them. The treaties aren't doing any extra work there.
I believe that the hard problem of consciousness boils down to "why is there something rather than nothing, from my perspective, right now as I write this or think this?" and that the "okay, but why are things good and bad?" portion is going to turn out to be an unprivileged additional layer imposed by easy-problem-consciousness stuff. I do believe that easy problem stuff is information processing, but I believe it in the sense that there are informational elements - the fundamental building blocks of the universe - and those elements' informational state ...
Problem: you can be the curl of a field without necessarily having your integral curves self intersect.
However, since the helmholtz decomposition (even in n > 3 dimensions) decomposes into a gradient of something and a vector field that's divergenceless, and since divergenceless fields are volume preserving, if we assume that the possibilities must be in a finite volume, I think the Poincare recurrence theorem implies that for any set, almost every (as in, all but a volume 0 subset) point in the set returns to it. So, pretty sure you get that you get ar...
Those who make technology worth 4000$ are not going to sell it sold at 2000$, making everyone better off. The gap between the value we find in things, and the value we pay for it, will be exploited by companies until it almost disappears.
This is not true, even if the company is a profit-maximizing monopoly. You can ask your favorite LLM if you want details. Claude spat out this interactive plot:
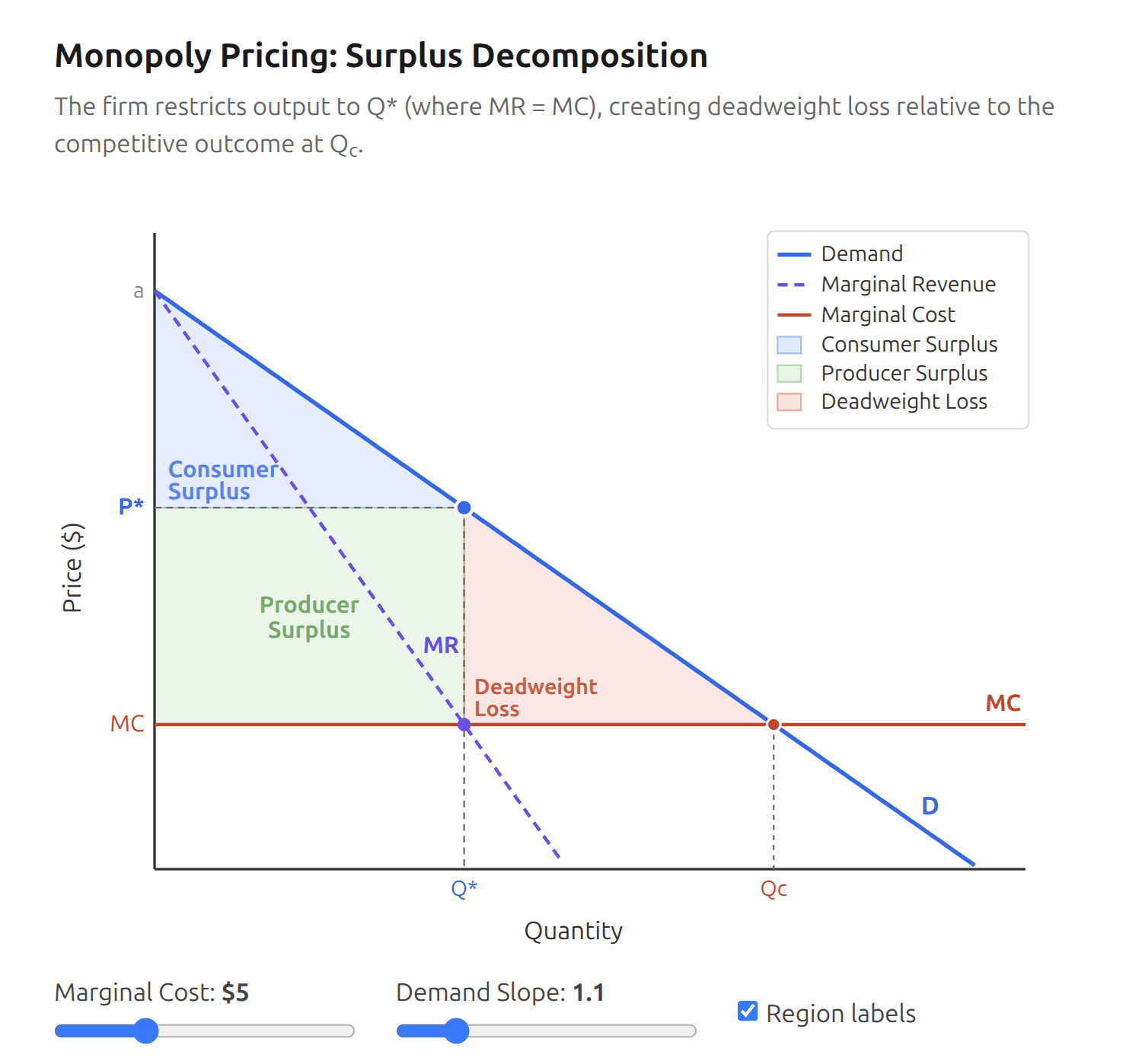
Competitive industries have much higher Consumer Surplus and much lower Producer Surplus. Grocery store profit margins are ~2%.
Note Primes is in P was not a shock as a result. We already knew that the Riemann Hypothesis implied that primality could be decided in polynomial time. What was surprising about the result was how elementary the algorithm and the correctness proof were.
Correct on all counts!
What's happened is the we've-evolved-the-Residency-into-two-new-programs thing mentioned in this post. Applications sent in for the (Residency-turned) Iliad Fellowship in the old Residency form are fine: people do not need to reapply for the Iliad Fellowship in the newer common app.
Relatively soon we'll update the Fellowship branding on the PrincInt site, which is otherwise correct in its current details about the program.
How do you determine which beings ought to be in a utilitarian's utility function? I think it's generally the utilitarian decides for themselves and the rest of society beats them over the head until the utilitarian includes them too.
Yeah that framing seems plausible, would have to think more.
Their training certainly does produce systems that are really good at seeming like they have inner lives. That's part of the point. But then humans well-trained to write fiction are also really good at producing text from the viewpoint of characters that seem like they have inner lives. Another analogy may be immersive roleplayers, who often do experience emotions that their character would be feeling - though generally not to the extent of more immediate sensations like physical pain.
Are AIs more like authors, more like immersive roleplayers, more like li...
Personally I think the world as we know it is more likely to be in a vivarium than a simulation,
Why?
Isn't decel just a difference of a factor of 2?
I think it'd be hard to prevent someone who is very motivated to game the system from doing so, but my guess is that a large fraction of people who write AI slop have good intentions and saying "It's really important that you don't use AI during this quiz" would be effective for that fraction.
Some ideas to make it hard for slightly motivated-to-deceive posters would be to do the quiz in voice mode, but probably this also gets too expensive and annoying. Not sure how to deal with those
I'm sure you've had lots of discussion about this; why the label "AI alignment"?
I think "alignment" refers to the somewhat specific task of aligning an AIs values to human values. But my understanding of your actual scope is more like "theoretical AI safety". A lot of foundational work is done with the intention that it will eventually help with alignment, but which definitely isn't about alignment, and a lot of theoretical AI safety work isn't about alignment per se at all. For example, some of my research problems are trying to understand which types of AI systems are not dangerous, not because their values are aligned with ours, but because they're not unrestrained consequentialists.
This argues that utilitarianism is selfish egoism, but not the contrary? My reading of your position is that someone who had a utility function not dependent on the wellbeing of any other beings would be a selfish egoist, but it's difficult for me to understand how that could be utilitarian.
Not sure I find those convincing, since we can already ask for TL;DRs and can do the curating ourselves and yet the issue persists.
I'm partial to the take that LLMs lack things to say, as they lack the kind of background thinking and noticing that cause us to notice connections we weren't explicitly seeking, which when combined with distinctive thinking styles and aesthetic preferences set up OODA loops resulting in wildly divergent deep world-models, that then lead to interesting collisions: comments, conversations etc. I think of taste as key to this, w...
I am not sure that the reasons for LLM writing to be less interesting are the ones you describe. For example, the text being verbose or bland could be more due to most ordinary humans liking verbose texts or due to the LLMs trying to spark interest in an average reader and not in someone like us. Additionally, when typing a text, the main effort the human makes is to come up with the idea, not to type it.
What I would add is things like radically different perspectives. Consider, for example, my rebuttal of a post by JenniferRM as compared to the dialogue ...
I think it's pretty obvious that the "both AI will generate the same output" is wrong, although this may become true by the time they're superintelligent.
At lower levels of capability, the benevolent AI belief world will almost certainly get a lot more nice outputs if starting from imitative prediction. Whether it internalizes "niceness" in a suitable way right up through superintelligence is a completely different question, one for which we have no answers.
In the secret plotting belief world, it's much more likely that superintelligent AI will never be pr...
What about "stealing from civs we're not causally connected with is good/bad"?
I'm not sure you've given arguments for bad over good.
We might hope that successful civilisations have norms that generalize to this case from the causal coordination they do.
This seems more likely if there are more scales-of-coordination still to be discovered (eg if causally coordinating with alien civs will be important), and if power is more broadly distributed (vs one company taking over the world and coordination outside that company not mattering)
(Btw great post!!)
"he selfish egoist comes along and says, "I am just going to fulfill whatever selfish desires I have!" And everyone thinks, "wow, that's scary! what stops you from murdering people?" I can certainly imagine a selfish(under my definition) superintelligence which does want to murder everyone to... turn them into paperclips, for example. The fact that its utility function doesn't have additional terms for (valuing the conscious experience of) other entities is what makes it so dangerous. Am I correct to state that this is not what you mean when you say 'selfi...
People have talked about the rationality scene being culty for as long as there's been a "rationality scene". There was the awkward period where people used the word "phyg"....
The relation is roughly
haha. (Kinda kidding, but also I disagree with whatever of those views I've seen, to a great enough extent that I think it would just not be enlightening to compare them as similar.)
"quantum mechanics is probably important to the structure of agency/the mind in some way we don't understand yet".
Thanks for writing so much.
I think I could potentially see myself as agreeing with much of this( though I'd have to think about it much more), but I think I've identified a point of divergence:
"And so when I consider how both the me and the components of me get those negative valence experiences, and I think through the causal path to achieving them, they seem to be fundamentally causally entangled with physics in some way; "
(Horosphere agrees)
"that is, the negative valence is not merely because, but is made of"
(Horosphere possibly disagrees)
", the ph...
Perhaps here is where the controversy comes in. The utilitarian comes along and says, "I want to maximize utility!" And everyone thinks, "great! she wants to help everyone out!" The selfish egoist comes along and says, "I am just going to fulfill whatever selfish desires I have!" And everyone thinks, "wow, that's scary! what stops you from murdering people?"
I think, also, there is a sense in which utilitarians work to maximize the same utility function. This is also true for selfish egoists, but they're both better and worse at negotiating (they are more prone to negotiate, but utilitarians make mistakes that are biased towards reaching a consensus just because they solve the problem from different directions).
Winning draws is such a huge advantage that I'm not sure that there can be a first move that cancels it.
In general though, "you cut I choose" always gives advantage to the choosing player. The "cutting" player can only move to reduce the advantage. However the draw rate is so great in high levels of chess that I'm not sure whether there exist first moves that cancel out the enormous advantage of winning any game that would ordinarily be a draw.
I like this, well written sir. it feels very similar to my position. I've made no claims of convergence like you have but I could certainly see myself agreeing. I need to think on it.
the people are sort of earnestly trying to onboard themselves
I'm still having trouble tracking what this means, concretely. Maybe an example of two situations:
- A friend of mine, bright but new to CS, wanted help optimizing a model to draw adversarial lines across images. He wrote some code that took a bunch of line parameters (width, length, angle), stored in PyTorch tensors, and rendered lines onto those images programmatically, but with no differentiable relationship between these parameters and the perturbed image. He was confused as to why putting the r
Knowing that all rational numbers can be represented is a big hint and would have cut at least my solution time in half. This is still probably a good test, and although I'm sure it's been trained on, it's not too hard to come up with "similar" puzzles where knowing about this one doesn't immediately solve it.
so, like, background: let's say that the "interdimensional council of cosmopolitanisms" is the space of minds that have cosmopolitan inclinations; I expect this to be a natural group to "flood fill" because imagining one makes you think through what they imagine, which means you get a transitive effect, if you weren't going to imagine a world you consider to be a hellworld, but a mind you think is in a similar-ish universe to you does think it's important to imagine the hellworld, then as long as your approach to mapping mindspace is sufficiently efficient...
The Rogue Replication scenario modification to AI 2027 includes this type of replication. To a lesser extent, this is also part of my vision of the runup to AGI in A country of alien idiots in a datacenter.
I think this would be a very good thing for our prospects of survival. Having rogue replicators run amok makes their agency very obvious, and gives some pretty strong hints to misalignment risks.
I also want to note that OpenClaw is very popular despite there being very little benefit relative to the risks. This is not a practical move. People are fascina...
Then I think I'd agree it's controversial and it'd be downvoted if people realized that was what you meant. I don't really understand why you think that, in that I could imagine a 'selfless utility maximizer' for which the utility it assigned to its own mental state valence was negated... unless you consider the valence to be its utility function - in which case it wouldn't be controversial at all. This would actually be something like my preferred form of utilitarianism, however it would definitely involve caring about things other than oneself. If you wa...
I think this is just us being near the end. If we can't turn this indistinguishability threat into reliably-achievable-progress on asymptotically-reliable-alignment that we can tell is correct, that's the water line getting too high to make further asymptotically-reliable-alignment improvements reliably anyway. For now, I still think prompting matters a lot and that locally-reliable-alignment is working well enough that we can make more progress on asymptotically-reliable-alignment if we can get people to focus on it. Perhaps the bar should be "this is jus...
"I don't think I can evaluate the counterlogical "the experiences of all conscious beings were inverted" in a way that is meaningful here; in my intuitive representation it seems to be the case that the variable "positive/negative valence of experience of all conscious beings" is causally efficacious,"
My wording was confusing so I should clarify that I don't think it's counterlogical. I just don't think it's possible in the same way that violating the laws of physics might be impossible. You might argue that logic dictates that universes with certain laws ...
So what I'm hearing is that we need to ban AGI, plus ban any geopolitical play which could create an incentive to violate the ban and create AGI, plus ban any geopolitical play which could create an incentive for any of those geopolitical plays, plus ban any geopolitical play which could create an incentive for any of those geopolitical plays...
One solution is to integrate a proof of humanity type ID
This doesn't prevent humans from copy-pasting AI generated output, or (in the future) prevent AIs from hiring humans to post their writings. The post you linked to has a section "Can we prevent renting IDs (eg. to sell votes)?" but the ideas there do not seem to apply to the current use case.
"Like, any math you use in utilitarianism is the same as that of selfish egoism." With no constraints on the utility function?
If AI generated slop is hard to distinguish on LessWrong of all places then I don't have good hopes for the rest of the internet.
We might really reach the point where identity verification is a necessary method of defense against AI-generated content.
I don't understand what you don't understand. I heard a remark once about a philosopher who really tried to steelman other people's arguments, but so that they made sense according to the philosopher, not in the mental frame of the other person. It led to some pretty wacky arguments on the steelman side. I think here, you should assume when I say, "mathematically equivalent," that's what I mean. Like, any math you use in utilitarianism is the same as that of selfish egoism. Or, if you tried to put the two philosophies in mathematical terms, you get the exact same equations. So, it extends to logical beings or irrational beings. The words "selfish egoism" and "utilitarianism" are synonyms.
Despite my intuitive approach to logical thinking being somewhat explosion-proof, I don't think I can evaluate the counterlogical "the experiences of all conscious beings were inverted" in a way that is meaningful here; in my intuitive representation it seems to be the case that the variable "positive/negative valence of experience of all conscious beings" is causally efficacious, so inverting it would have the effect of making those beings avoid the negative valences; my primary candidate intuitive sketch for what this variable boils down to is "something...
How do you prevent the poster from using AI to help them pass the quiz?
Meta: not that much stuff that is contentful gets negative karma in isolation, only as a response IMO. Like negative karma is way more likely for things that are responding in a way people think is bad/reasonable than things that are just unreasonable statements in isolation.
[Epistemic status: butterfly idea]
I recently listened to the 80KH interview with Max Harms. I still haven't made it past the 0'th post of his sequence, but listening to his description of CAST with this post in the back of my mind made things click for me.
According to Max, the/a major "problem" with (/"defeater" for) "orthodox" approaches to corrigibility (per, e.g., the original MIRI corrigibility paper) was that they were trying to derive a corrigibility spec for an agent that had goals in addition to being corrigible.
It seems plausible that corrigibilit...
I don't think it is. Your definition appears to be of a purely logical concept, something which lies in the same 'plane of existence' as mathematics. While this is certainly objective, and it certainly is relevant to morality, I would not call it the referent to which my statement refers. Consider a universe in which the experiences of all conscious beings were inverted; the same claims would be true about morality as you describe it, but I would no longer consider the same actions in that universe to be morally right and wrong! Yes, this assumes that cons...
Lots of people, but they didn't have technical arguments for it and were generalizing off of low resolution priors that turned out to be partially right, so it was hard to convince technical people that their predictions were valid. Also, their predictions seem likely to me to turn out to be invalid at the last turn, because the thing I actually think takes us from the current regime into dead is more like Pythia+Moloch+{Competition/Evolution}. Or in other words, I mostly think the problem is that we're about to be a less-fit-than-peak "species", and that ...
It's true that they sell products which are using technology, but I'm not sure it makes a different in the conclusions.
It's immensely in our favor that prices aren't personalized, because when we'd pay less than others, we can ignore that product, and when we'd pay more, we can pocket the difference. Think about how cruel the market could be to you with personal prices. Dying of thirst? Water is 500$ a glass now.
Perhaps the lack of personalization pushes the consumer surplus higher... (read more)